
[AI] 구글 오픈 AI, 젬마(Gemma) Python으로 사용해 보기

ㅁ 들어가며
2024.2.21 구글의 Gemma가 공개 되었습니다. 관련 구글블로그
Gemma는 Gemini 모델을 만드는 데 사용된 것과 동일한 연구 및 기술을 바탕으로 제작된 경량 AI입니다.
고은별님의 Python - 구글의 오픈 AI 모델 젬마(Gemma) 사용하기 글을 참조하였습니다.
ㅁ Gemma란?
Gemma는 Gemini 모델을 만드는 데 사용된 것과 동일한 연구 및 기술을 바탕으로 구축된 Google의 경량 최첨단 개방형 모델 제품군입니다. Gemma 모델은 질문 답변, 요약, 추론을 포함한 다양한 텍스트 생성 작업에 매우 적합합니다. 상대적으로 작은 크기로 인해 노트북, 데스크톱 또는 자체 클라우드 인프라와 같이 리소스가 제한된 환경에 배포할 수 있으며, AI 모델에 대해 모든 사람이 사용할 수 있도록 경량화 되었습니다.
텍스트 생성에 Gemma 모델을 사용할 수 있지만 특정 작업 수행에 특화되어 있도록 이러한 모델을 조정할 수도 있습니다. 조정된 Gemma 모델은 개발자와 사용자에게 보다 타겟팅된 효율적인 생성형 AI 솔루션을 제공할 수 있습니다.
ㅁ 모델 크기 및 기능
Gemma 모델은 2B와 7B 두가지 크기로 제공되므로 사용 가능한 컴퓨팅 리소스, 필요한 기능, 실행 위치에 따라 생성형 AI 솔루션을 빌드할 수 있습니다. 모델 배포 위치를 더 유연하게 설정할 수 있도록 2B 크기를 사용하기를 권장합니다.
| 매개변수 크기 | 입력 | 출력 | 조정된 버전 | 사용 대상 플랫폼 |
| 2B(20억) | 텍스트 | 텍스트 | - 선행 학습 - 안내 조정됨 |
휴대기기 및 노트북 |
| 7B(70억) | 텍스트 | 텍스트 | - 선행 학습 - 안내 조정됨 |
데스크톱 컴퓨터 및 소형 서버 |
ㅁ 조정된 모델
Gemma 모델은 명령 조정 버전과 사전 학습된 버전에서 모두 사용할 수 있습니다. 추가 학습을 통해 Gemma 모델의 동작을 수정하여 특정 태스크에서 모델 성능이 향상되도록 할 수 있습니다. 이 프로세스를 모델 조정이라고 합니다. 이 기법을 사용하면 모델의 대상 작업 수행 능력이 향상되지만 다른 작업에서는 모델 성능이 저하될 수 있습니다.
ㅁ 시작 가이드
Gemma를 사용한 솔루션 빌드를 시작하려면 다음 가이드를 확인해 보세요.
- Gemma로 텍스트 생성 - 모델을 사용하여 기본 텍스트 생성 예를 빌드합니다.
- LoRA 조정으로 Gemma 조정 - Gemma 2B 모델에 LoRA 세부 조정을 수행합니다.
- 분산 학습을 사용하여 Gemma 모델 조정 - Keras를 JAX 백엔드와 함께 사용하여 LoRA 및 모델 동시 로드로 Gemma 7B 모델을 미세 조정합니다.
- 프로덕션에 Gemma 배포 - Vertex AI를 사용하여 Gemma를 프로덕션에 배포합니다.
저는 고은별님의 Python - 구글의 오픈 AI 모델 젬마(Gemma) 사용하기 글을 참조하여 로컬에서 테스트를 진행해 보았습니다.
ㅁ Hugging Face 설정
ㅇ Hugging Face 가입
ㄴ Gemma 모델을 사용하기 위해 huggingface에 가입하였습니다.
ㅇ Gemma 라이센스 승인
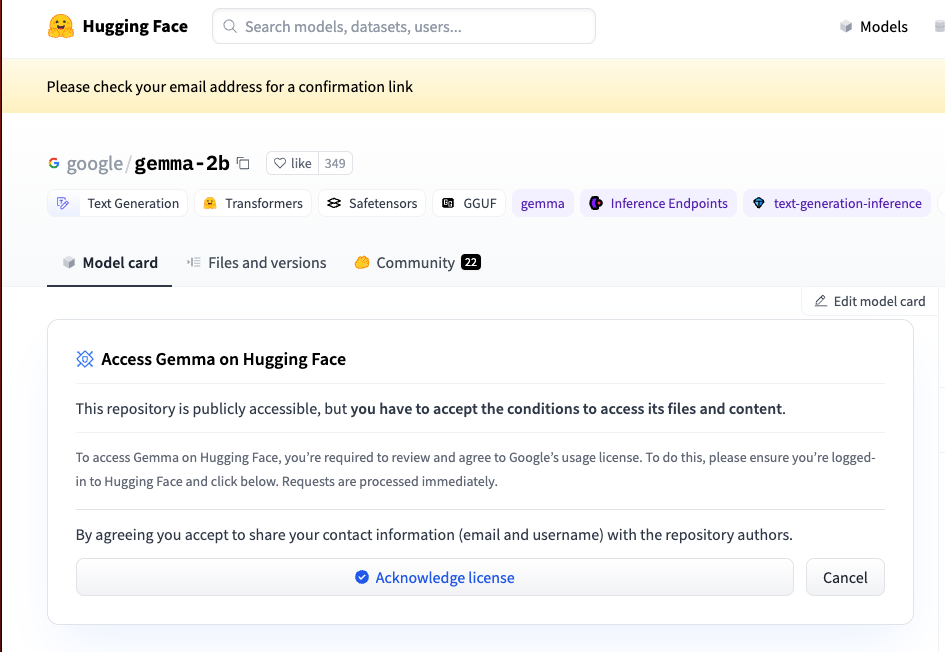
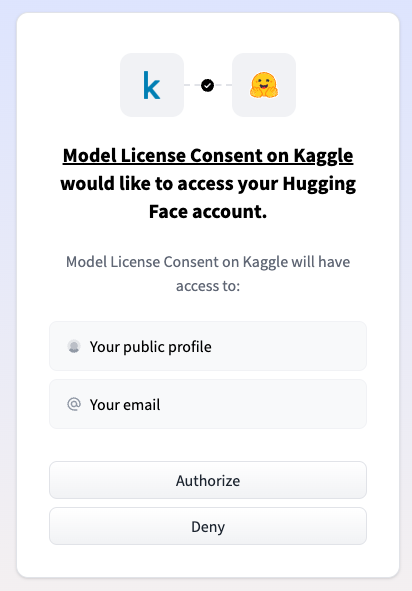
ㄴ google/gemma-2b로 이동하여 라이센스 승인을 받습니다.
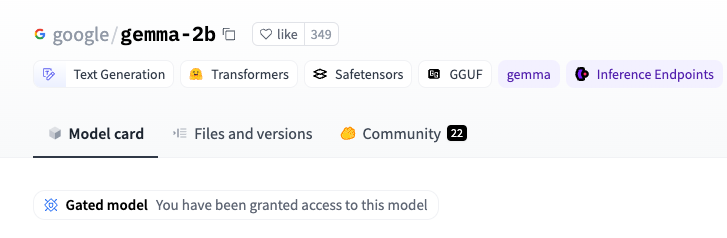
ㄴ Gated model에 접속할 수 있는 권한을 받았습니다.
ㅇ Huggin Face 액세스 토큰 만들기
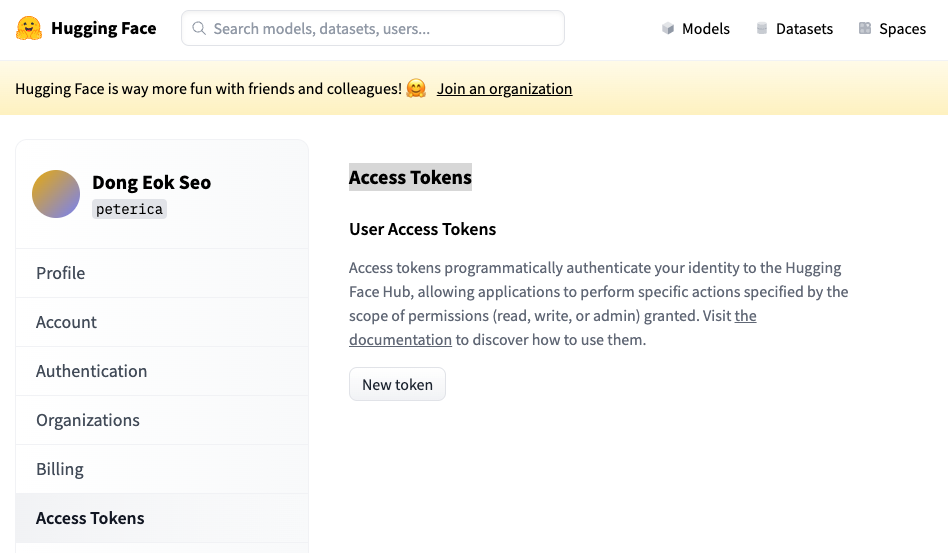
ㄴ Access Token페이지로 이동합니다.
ㄴ read_token이란 이름으로 토큰을 생성하였습니다.
ㅁ Gemma을 위한 파이썬 설정
ㅇ Hugging Face CLI 설치
$ pip install -U "huggingface_hub[cli]"
ㅇ Hugging Face CLI 로그인
$ huggingface-cli login
_| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|
_| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|
_| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|
To login, `huggingface_hub` requires a token generated from https://huggingface.co/settings/tokens .
Token:
Add token as git credential? (Y/n) y
Token is valid (permission: read).
Your token has been saved in your configured git credential helpers (osxkeychain).
Your token has been saved to /Users/peterseo/.cache/huggingface/token
Login successfulㄴ Huggin Face 액세스 토큰을 복사하여 로그인 한다.
ㅇ Hugging Face Transformers 라이브러리 설치
pip install git+https://github.com/huggingface/transformers
ㄴ 설치 문서는 이곳
ㅁ 파이썬에서 Gemma 실행하기
ㅇ huggingface의 google/gemma-2b의 사용예제를 이용하여 실행해 보았습니다.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
UserWarning: Using the model-agnostic default `max_length` (=20) to control the generation length. We recommend setting `max_new_tokens` to control the maximum length of the generation.ㅇ 샘플 구문자체가 최대 20을 넘어서면 에러가 발생하였습니다.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b")
input_text = "Tell me about you"
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids, max_length=100)
print(tokenizer.decode(outputs[0]))ㅇ input_text의 내용과 max_length을 100으로 수정하였습니다.

<bos>Tell me about you.
I am a 20-year-old student from the United States.
I am currently studying at the University of California, Berkeley.
I am majoring in Political Science and minoring in Economics.
I am also a member of the Berkeley Model United Nations team.
Tell me about your research.
I am currently working on a research project that focuses on the relationship between the United States and China.
I am specifically looking at how the United States has responded toㅇ input_text의 내용과 max_length을 수정하여 다시 진행하였을 때에 성공하였습니다.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b")
input_text = "Tell me about you"
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids, max_length=300)
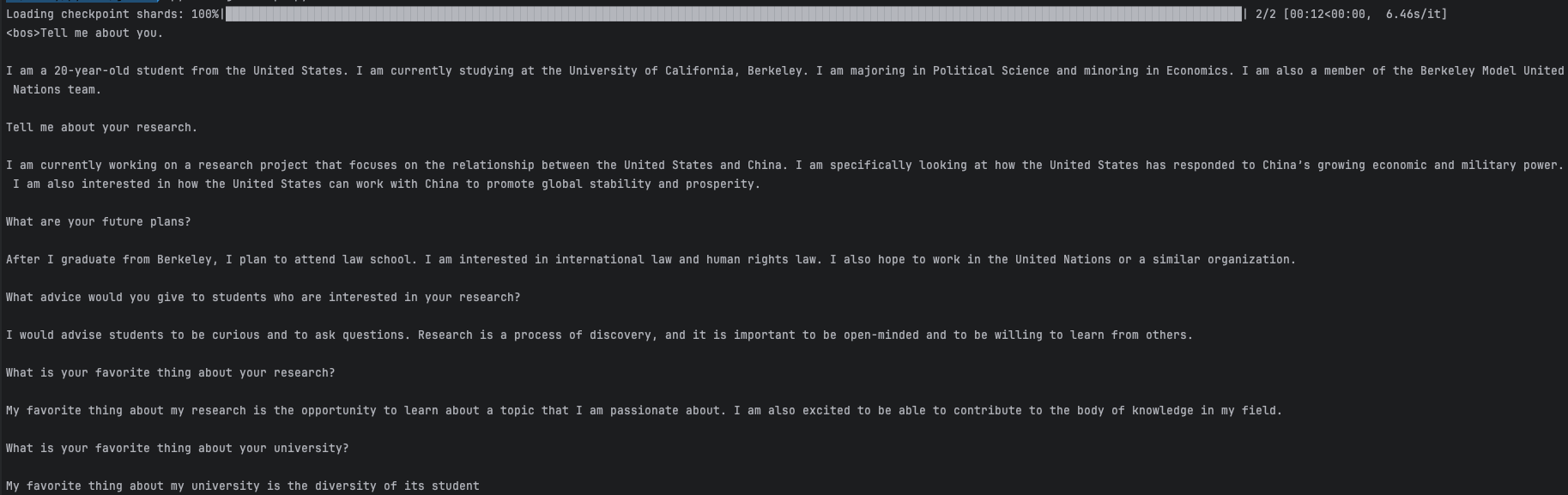
print(tokenizer.decode(outputs[0]))ㅇ output의 길이가 100에서 짤려진듯하여 300으로 늘려서 다시 수행해 보았습니다.
<bos>Tell me about you.
I am a 20-year-old student from the United States. I am currently studying at the University of California, Berkeley. I am majoring in Political Science and minoring in Economics. I am also a member of the Berkeley Model United Nations team.
Tell me about your research.
I am currently working on a research project that focuses on the relationship between the United States and China. I am specifically looking at how the United States has responded to China’s growing economic and military power. I am also interested in how the United States can work with China to promote global stability and prosperity.
What are your future plans?
After I graduate from Berkeley, I plan to attend law school. I am interested in international law and human rights law. I also hope to work in the United Nations or a similar organization.
What advice would you give to students who are interested in your research?
I would advise students to be curious and to ask questions. Research is a process of discovery, and it is important to be open-minded and to be willing to learn from others.
What is your favorite thing about your research?
My favorite thing about my research is the opportunity to learn about a topic that I am passionate about. I am also excited to be able to contribute to the body of knowledge in my field.
What is your favorite thing about your university?
My favorite thing about my university is the diversity of its studentㅇ 수행결과가 정상적으로 확인되었습니다.
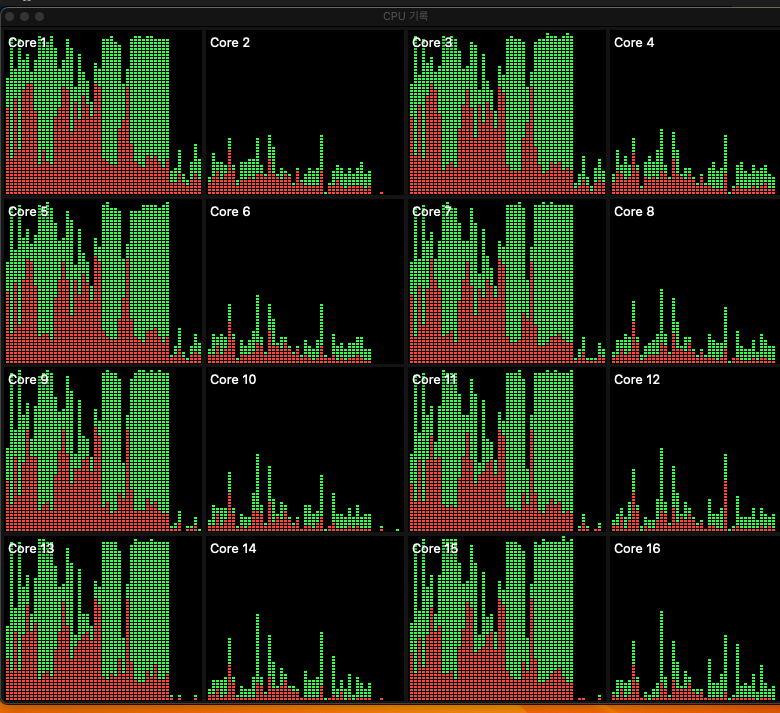
ㅇ CPU를 사용하는 모델을 이용해 시스템 모니터링을 해 보았습니다.
ㅇ 16코어 모두 사용하였고, 시간은 10분 36초가 소요되었습니다.
ㅁ 마무리
AI를 오픈형테로 제공하는 구글의 Gemma를 사용해 보았습니다. 아직 시작단계인 AI가 보다 개인이나 기업에 친숙한 모델로 발전하는 모습을 보면서 다가오는 미래에 JAVA처럼 일상적인 모델로 다가올 수 있다는 가능성을 확인해 보는 시간이었습니다.