[AI] 최근 대규모 언어 모델(LLM)의 급격한 성장 이유

ㅁ 들어가며
ㅇ [AI] 언어 모델의 병렬처리를 가능하게 한 트렌스포머(Transformer) 기술에 대해서 정리하였다.
ㅇ 2017년부터 대규모 언어 모델(Large Language Models, LLM)의 크기가 급격히 증가하는 이유에 대해서 정리해보았다.
ㅁ 언어 모델의 진화
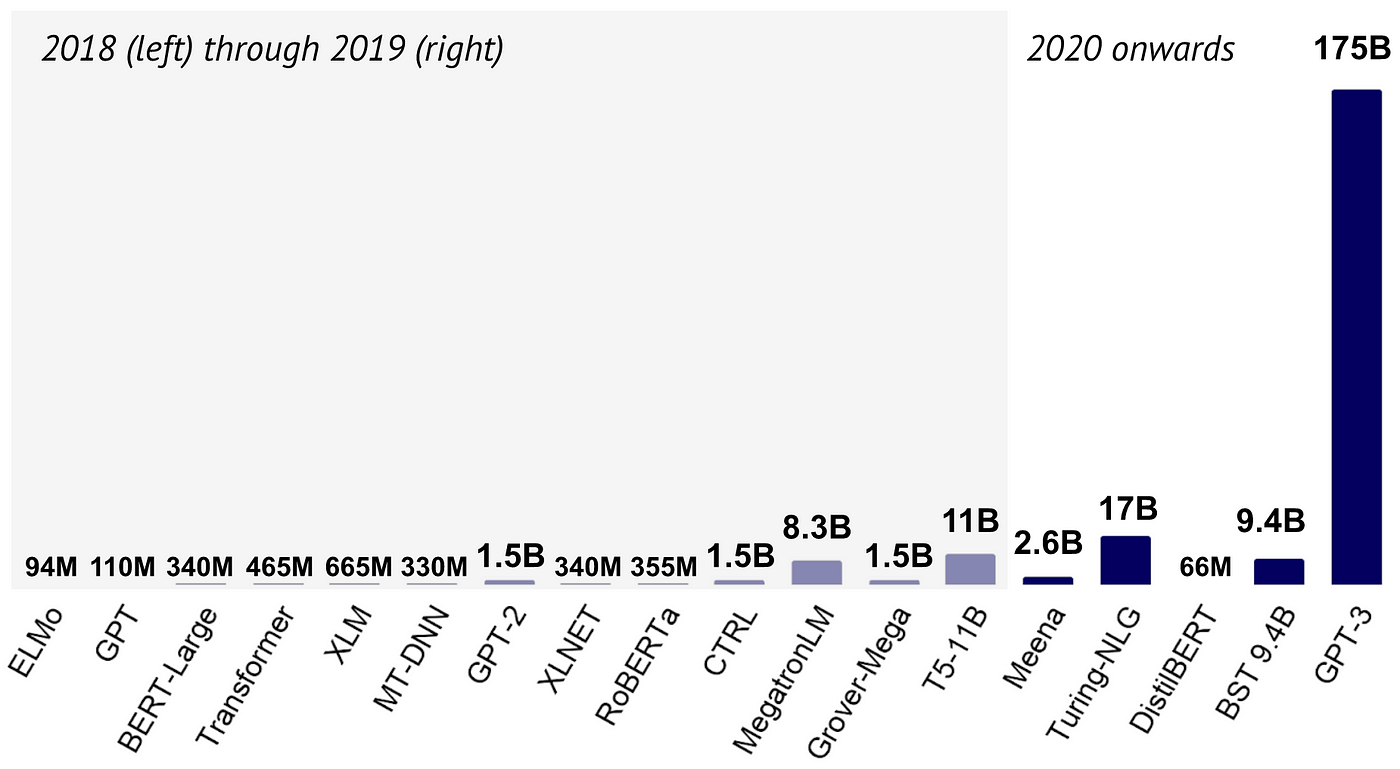
ㅇ 2017년 Transformer 모델이 등장한 이후, 언어 모델의 크기는 폭발적으로 증가했다.
- Transformer (2017): 465M 파라미터
- GPT-3 (2020): 175B 파라미터 (Transformer의 376배)
- Switch-C (2021): 1.6T 파라미터
- Wu Dao 2.0 (2021): 1.75T 파라미터 (GPT-3의 10배)
- GPT-4(2023): 1.8T 파라미터 (GPT-3의 10.3배)
- 인간의 뇌(100Tb)
ㅁ 성능 향상의 핵심 요소
ㅇ OpenAI의 연구에 따르면, 언어 모델의 성능은 주로 세 가지 요소에 의해 결정된다.
1. 모델 파라미터 수 (N)
2. 데이터셋 크기 (D)
3. 학습에 필요한 컴퓨팅 능력 (C)
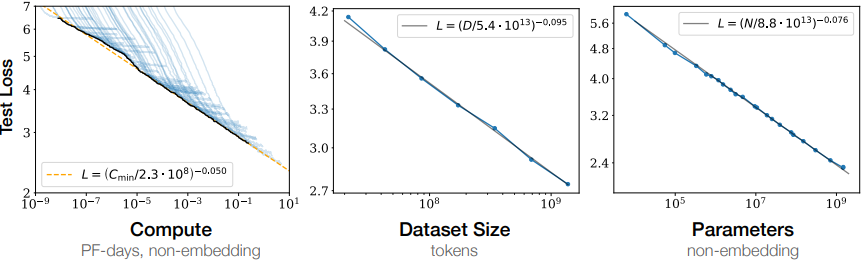
ㅇ 흥미롭게도, 모델의 구조적 하이퍼파라미터(예: 깊이 vs 너비)는 성능에 큰 영향을 미치지 않는다.
ㅇ 성능 패널티는 (N^0.74)/D에 의존한다. 즉, 모델 사이즈가 8배 증가할 때 데이터셋은 약 5배가 증가해야 패널티를 피할 수 있다.
ㄴ. N 또는 D 중 하나가 고정된 채 다른 scale factor가 증가하면 고정된 scale factor가 패널티로 작용하여 성능 증가가 감소된다.
ㅁ 최신 대규모 언어 모델(LLM)이 급격하게 커지는 이유
1. 성능과 스케일 요소의 관계
언어 모델의 성능은 위 세 가지 스케일 요소와 멱법칙(power-law) 관계를 가진다.
2. 균형 잡힌 스케일링의 중요성
모델 크기(N)와 데이터셋 크기(D)를 동시에 증가시킬 때 성능이 가장 잘 개선된다.
한 요소만 증가시키면 성능 향상에 제한이 생긴다.
3. 대규모 모델의 효율성
큰 모델은 작은 모델보다 샘플 효율성이 높아, 더 적은 데이터와 최적화 단계로 동일한 성능에 도달할 수 있다.
4. 대규모 데이터의 가용성
인터넷의 발달로 방대한 양의 텍스트 데이터를 수집하고 학습에 활용할 수 있게 되었다.
5. 트랜스포머 아키텍처의 확장성
트랜스포머 모델은 규모를 키우기 쉬운 구조를 가지고 있어 대규모 확장이 용이하다.
6. 다양한 작업 수행 능력
더 큰 모델은 다양한 NLP 작업을 단일 모델로 수행할 수 있는 능력을 갖추게 된다.
ㅁ 마무리
최근 언어 모델들이 급격하게 커지고 있는지를 살펴보았다. 더 큰 모델과 더 많은 데이터를 사용하면 성능이 지속적으로 향상되며, 대규모 모델이 학습 효율성도 높기 때문이다. 그러나 이는 동시에 엄청난 컴퓨팅 자원과 대규모 데이터셋이 필요함을 의미한다. 따라서 앞으로의 언어 모델 발전은 컴퓨팅 능력의 향상과 대규모 고품질 데이터셋의 확보에 크게 의존할 것으로 보인다. 이러한 트렌드는 당분간 계속될 것으로 예상되며, 더욱 강력하고 다재다능한 언어 모델의 등장을 기대해볼 수 있다.
ㅁ 함께 보면 좋은 사이트
ㅇ 왜 최신 Language Model은 급격하게 커지는 것일까?
ㅇ 거대언어모델(LLM)의 현주소
ㅇ 대규모 언어 모델이 사용되는 이유는?
ㅇ 거대언어모델을 넘어 거대행동모델의 등장, LAM 시대