
[AI] 기계학습의 분류, 강화학습의 개념 정리

ㅁ 관련글
ㅁ 들어가며
ㅇ 인공지능(AI) 분야에서 기계학습(Machine Learning)인 강화(reinforement)학습과 다른 기계학습은 두 가지 주요한 학습 방법이다.
ㅇ 말 그대로 Machine Learning은 인공지능을 학습 시키는 방법으로 두 가지 주요 방법은 각각 고유한 특성과 적용 분야를 가지고 있어 비교해볼 만한 가치가 있다.
ㅁ 기계학습의 분류
ㅇ 기계학습에는 지도학습과 비지도학습, 강화 학습으로 분류된다.
ㅇ 기계학습은 인공지능이라 부르기도 하고 데이터를 사용한다는 공통점이 있다.
ㅇ 데이터를 이용해 인공지능을 학습하는 방식의 차이에 따라 그 특징이 구분되어 진다.
ㅁ 지도학습 (Supervised Learning)
ㅇ 지도자 또는 정답이 주어져 있다.
ㅇ 입력값과 출력값의 관계를 학습한다.
ㅇ 입력값과 출력값이 모두 존재하는 데이터(labeled data)를 학습시키는 것으로 새로운 데이터가 주어졌을 때 데이터 기반으로 예측한다.
ㅇ 학습 데이터를 통해 예측 모델을 학습하고, 테스트 데이트를 통해 예측 모델의 성능을 평가한다.
ㅇ 예를 들어, 개와 고양이를 구분하는 AI 모델을 지도학습으로 만들어 보자.
ㅇ 우선, 개, 고양이 사진들을 인공지능에 학습시켜, 예측 모델을 생성한다.
ㅇ 테스트로 생성된 예측 모델에 개 사진을 모델에 적용했을 때 잘 판단하는지 여부로 성능을 측정할 수 있다.
ㅁ 비지도학습(Unsupervised Learning)
ㅇ 정답이 없다.
ㅇ 정답이 없는 데이터에 숨겨진 통계적 구조를 학습한다.
ㅇ 입력값만 존재하는 데이터(unlabeled data)를 학습시키는 것으로 비슷한 특징끼리 군집화 하여 새로운 데이터에 대한 결과를 예측한다.
ㅇ 정답이 없는 데이터를 학습한다는 점에서 강화학습과 유사하지만 강화학습은 보상신호가 있다는 점에서 다르다.
ㅇ 생성형 모델: 이미지를 입력하면 인공지능에 의해 향상된 이미지를 얻을 수 있다.
ㅇ 클러스터링 모델: 입력된 데이터들의 공통점을 분석하여 그룹화하는 모델
ㅁ 강화학습(Reinforcement Learning)
ㅇ 강화학습은 행동적인 머신러닝이며 옳은 행동을 했을 때 보상을 받음으로써 훈련을 시키는 것이다.
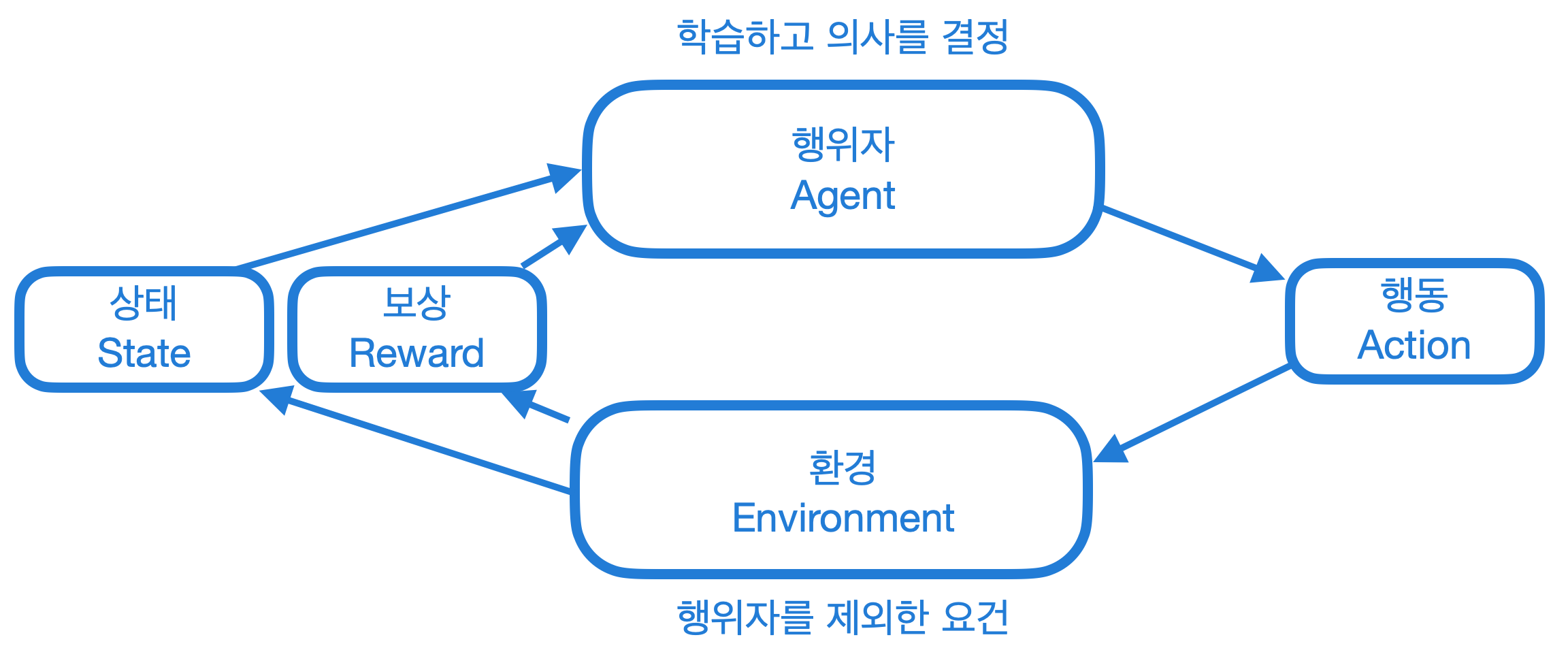
ㅇ 즉, 어떤 환경 안에서 정의된 주체(agent)가 현재의 상태(state)를 관찰하여 선택할 수 있는 행동(action)들 중에서 가장 최대의 보상(reward)을 가져다주는 행동이 무엇인지를 학습하는 것이다.
ㅇ 지도학습과 유사하다고 하지만 labeled 데이터가 아닌 환경과의 상호작용을 통해 얻는 보상으로부터 학습한다는 점에서 차이가 있다.
ㅇ 다시 말해, 지도학습의 데이터는 주어진 데이터이고, 강화학습은 주어진 데이터 + 경험에서 주어지는 데이터를 복합적으로 분석한다.
ㅇ 강화 학습의 예로는 게임, 알파고 등이 있다.
ㅁ 기계학습(지도, 비지도 학습)과 강화학습의 특징 비교
| 기계학습 | 강화학습 | |
| 정의 | 데이터로부터 패턴을 학습하여 예측이나 의사결정을 수행하는 AI 기법 | 에이전트가 환경과 상호작용하며 시행착오를 통해 학습하는 AI 기법 |
| 학습 방식 | 주로 지도학습, 비지도학습, 준지도학습으로 구분 |
에이전트의 행동에 대한 보상과 처벌을 통한 학습 |
| 데이터 의존성 | 대량의 레이블된 데이터셋 필요 | 실시간 상호작용을 통한 경험 데이터 생성 |
| 학습환경 | 학습 데이터와 살제 데이터가 구분된 상태에서 학습진행 | 학습 데이터의 별도 구분 없음 (시행착오를 통해 축적된 에피소드를 학습에 활용) |
| 목표 | 주어진 데이터에서 일반화된 패턴 추출 | 장기적인 보상을 최대화하는 최적의 정책 학습 |
| 적용 분야 | 이미지 인식, 자연어 처리, 추천 시스템 등 | 게임 AI, 로봇 제어, 자율주행 등 |
ㅁ 기계학습과 강화학습의 주요 차이점
| 기계학습 | 강화학습 | |
| 학습 과정 | 정적인 데이터셋을 사용하여 일괄 처리 방식으로 학습 | 동적인 환경에서 실시간으로 학습하며 정책을 개선 |
| 피드백 메커니즘 | 주로 오차나 손실 함수를 통한 간접적 피드백 | 행동에 대한 직접적인 보상이나 처벌을 통한 피드백 |
| 문제 유형 | 분류, 회귀, 군집화 등 정형화된 문제에 적합 | 순차적 의사결정 문제나 장기적 전략이 필요한 문제에 적합 |
| 데이터 요구사항 | 대량의 레이블된 데이터가 필요 | 초기 데이터셋 없이도 학습 가능, 단 충분한 탐색 시간 필요 |
| 적응성 | 학습 후 환경 변화에 대한 적응이 어려움 | 지속적인 학습을 통해 변화하는 환경에 적응 가능 |
ㅁ 강화학습과 지도학습의 비교
ㅇ 지도학습
- 구체화된 작업을 수행하는 성능 지향적 AI 모델을 학습
- 주어진 학습 및 테스트 데이터 환경에서 최적의 성능을 보이는 파라미터 학습
ㅇ 강화학습
- 전체적으로 상호작용적인 목표 지향적 AI 모델을 학습
- 주변 상황에 따른 행동을 학습
- 학습자는 목적에 맞는 명확한 학습목표 설정
- 사용자의 의도를 인공지능 모델에 반영 가능
- 순차적 의사결정 문제에서 누적 보상을 최대화하기 위해 실제 환경에서의 시행착오(trial-and-error)를 통해 행동을 교정
ㅁ 강화학습의 탐색(ploration)과 활용(Exploitation) 딜레마
ㅇ 탐색
- 이전에 선택하지 않았던 행동을 시도하여 새로운 정보를 얻는 과정이다.
- 더 큰 보상을 중점으로 선택.
ㅇ 활용
- 이미 알고 있는 정보를 바탕으로 보상을 극대화하는 행동을 선택하는 과정이다.
- 현재의 보상에 만족하고, 안정성을 중시한다.
ㅁ 마무리
기계학습과 강화학습은 각각의 장단점과 적합한 적용 분야가 있다. 기계학습은 대량의 데이터에서 패턴을 추출하는 데 탁월하며, 강화학습은 복잡한 의사결정 문제를 해결하는 데 유용하다. 실제 응용에서는 문제의 특성에 따라 두 방법을 적절하게 선택하거나 결합하여 사용하는 것이 중요하다.
ㅁ 함께 보면 좋은 사이트