
- 분류 전체보기 (960)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- MySQL
- SRE
- 오블완
- PETERICA
- 컨텍스트 엔지니어링
- Linux
- 기록으로 실력을 쌓자
- Java
- Pinpoint
- golang
- tucker의 go 언어 프로그래밍
- LLM
- CKA
- 정보처리기사 실기 기출문제
- 코틀린 코루틴의 정석
- CloudWatch
- AI
- minikube
- 티스토리챌린지
- kotlin
- 바이브코딩
- go
- Kubernetes
- Spring
- APM
- 공부
- AWS EKS
- CKA 기출문제
- aws
- kotlin coroutine
- Today
- Total
피터의 개발이야기
[AI Infra] QNN 이해하기 — 왜 Snapdragon 스마트폰은 ‘얇은 클라이언트’가 아니라 ‘작은 AI 서버’가 되는가 본문
[AI Infra] QNN 이해하기 — 왜 Snapdragon 스마트폰은 ‘얇은 클라이언트’가 아니라 ‘작은 AI 서버’가 되는가
기록하는 백앤드개발자 2026. 1. 29. 23:04
ㅁ 들어가며
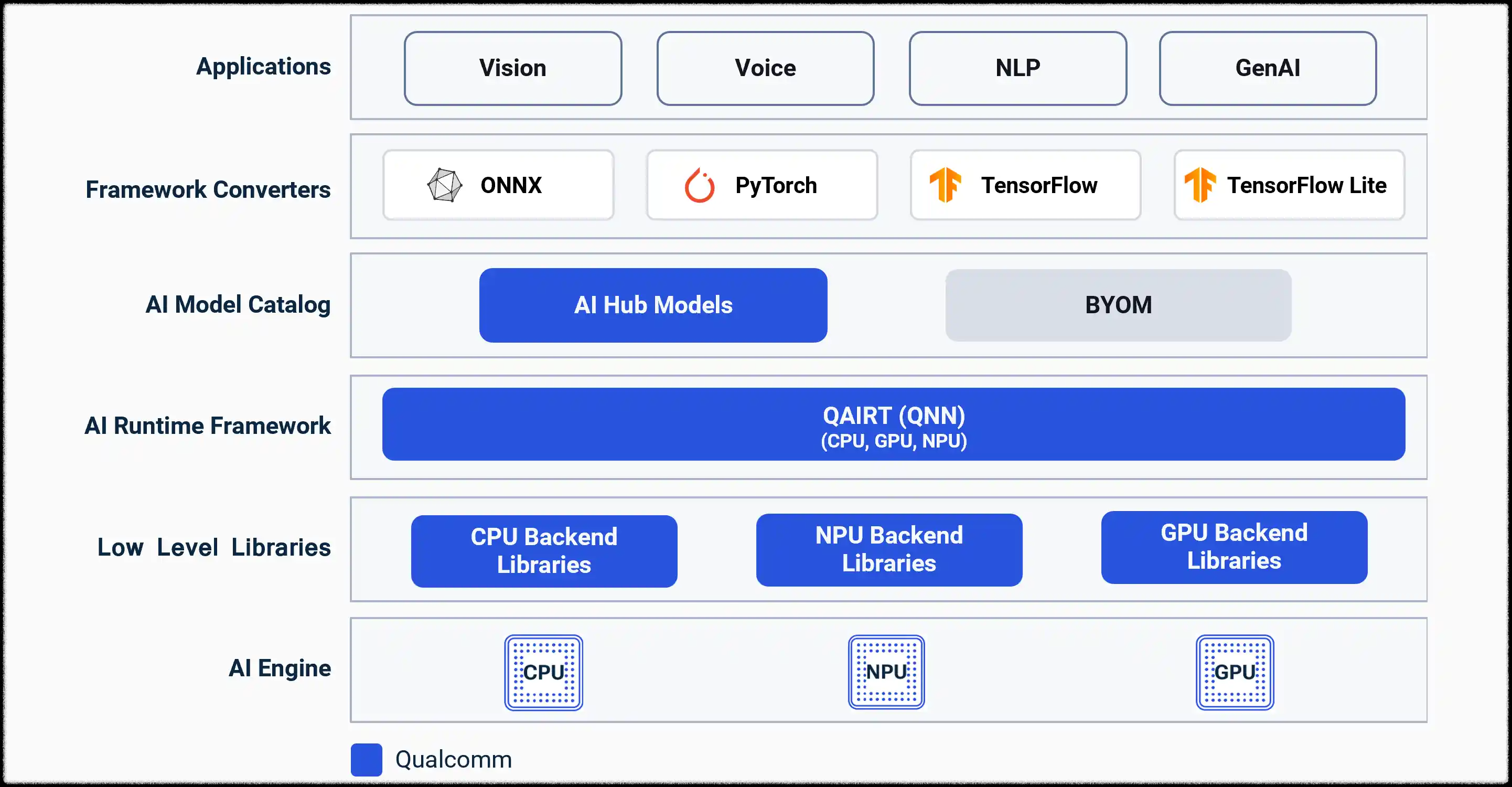
최근 컴포넌트 라이선스 검증과 SDK 구조를 살펴보는 과정에서 Qualcomm QNN(Qualcomm AI Runtime)을 접하게 되었다.
처음에는 단순한 모바일 AI SDK 정도로 생각했는데, 문서를 따라가며 구조를 이해하다 보니 QNN은 훨씬 본질적인 역할을 하고 있었다.
결론부터 말하면 QNN은 단순한 SDK가 아니라,
Snapdragon SoC 전체를 AI 추론용 컴퓨팅 플랫폼으로 만드는 런타임 레이어
에 가깝다.
이 글은 서버/JVM 개발자 관점에서 QNN을 이해한 기록이다.
ㅁ TL;DR
ㅇ Snapdragon은 이미 CPU / GPU / DSP / NPU가 공존하는 짬뽕 컴퓨팅 칩이다.
ㅇ QNN은 이 자원들을 하나의 AI 실행 환경처럼 묶어주는 추론 런타임이다.
ㅇ 구조적으로 JVM과 유사하다 (ONNX = bytecode, QNN Runtime = JVM).
ㅇ 그 결과 스마트폰은 “얇은 클라이언트”가 아니라 작은 AI 서버가 된다.
ㅁ Snapdragon은 이미 ‘이기종 서버’다
Snapdragon 내부에는 다음 유닛들이 동시에 존재한다.
- CPU : 범용 연산
- GPU : 벡터 연산
- DSP : 신호 처리
- NPU : 행렬 연산 특화
즉 하나의 칩 안에 서로 다른 성격의 연산 장치들이 공존한다.
서버 관점으로 보면:
- CPU
- GPU
- 전용 가속기
가 한 패키지에 들어있는 heterogeneous NUMA 머신과 유사하다.
ㅁ heterogeneous Non-Uniform Memory Access(NUMA)란
NUMA는 Non-Uniform Memory Access의 약자로,
연산 유닛마다 “가까운 메모리”와 “먼 메모리”가 존재해 접근 속도가 달라지는 구조를 의미한다.
여기에 heterogeneous(이기종) 가 붙으면,
- CPU뿐 아니라
- GPU, DSP, NPU 같은 성격이 다른 연산 유닛들이
- 각각 서로 다른 메모리 특성과 대역폭을 가지고 공존하는 구조를 뜻한다.
즉 Snapdragon은,
CPU / GPU / DSP / NPU가 각자 자기 영역(캐시·SRAM·메모리 경로)을 가진
초소형 이기종 NUMA 시스템
에 가깝다.
그래서 “어디서 실행하느냐”에 따라 성능과 전력 효율이 크게 달라지고,
이 복잡성을 개발자 대신 관리해 주는 레이어가 바로 QNN이다.
ㅇ Apple M 시리즈와 비교
Apple M 시리즈가 진짜 unified memory 구조라면,
Snapdragon은 CPU/GPU/NPU/DSP가 각자 다른 메모리 특성을 가진 이기종 구조이고,
QNN은 이 사이의 데이터 이동과 실행 배치를 담당하는 레이어다.
문제는,
이 구조를 애플리케이션 개발자가 직접 다루기에는 너무 복잡하다는 점이다.
여기서 QNN의 중요성이 나타난다.
ㅁ QNN은 AI 전용 JVM에 가깝다
JVM 구조를 먼저 떠올려보자.
Java
→ Bytecode
→ JVM
→ JIT
→ Native CPU
개발자는 하드웨어를 몰라도 된다.
JVM이 최적화를 담당한다.
QNN도 구조적으로 매우 비슷하다.
PyTorch / TensorFlow
→ ONNX
→ QNN Converter
→ QNN Runtime
→ CPU / GPU / DSP / NPU
대응시켜 보면 다음과 같다.
- ONNX = JVM bytecode
- QNN Converter = javac + AOT
- QNN Runtime = JVM
- NPU = JIT 이후 native execution target
차이점이 하나 있다.
JVM은 런타임 JIT 중심이고,
QNN은 사전 변환(AOT) + 런타임 오프로딩 중심이다.
하지만 역할은 동일하다.
모델을 분석하고, 분해하고, 가장 적절한 실행 유닛에 배치한다.
ㅁ QNN Runtime이 실제로 하는 일
QNN Runtime은 내부적으로 다음 작업을 수행한다.
- 모델 그래프 분석
- 연산 단위 분리
- CPU / GPU / DSP / NPU 매핑
- 메모리 이동 최적화
- fallback 처리
JVM 용어로 바꾸면:
- bytecode verification
- escape analysis
- scheduling
- JNI boundary 관리
와 같은 계열의 작업이다.
즉 QNN은 AI 추론 전용 HotSpot에 가깝다.
ㅁ 그래서 스마트폰은 ‘얇은 클라이언트’가 아니다
기존 모바일 구조는 다음과 같았다.
Client → Server → AI → Result
QNN 이후 구조는:
Device → QNN → NPU → Result
네트워크 왕복이 없다.
모델이 기기 내부에서 직접 실행된다.
이 말은 곧:
- 지연시간 감소
- 개인정보 외부 유출 없음
- 배터리 효율 극대화
를 의미한다.
그래서 이렇게 표현할 수 있다.
QNN 덕분에 스마트폰은 ‘얇은 클라이언트’가 아니라 ‘작은 AI 서버’가 된다.
ㅁ 서버 개발자 관점 정리
현재 내가 다루는 LLM-MAS, RAG, Ollama 같은 구조는 cloud / workstation 영역이다.
QNN은 edge 영역이다.
서로 경쟁 관계가 아니라 보완 관계다.
ㅇ 서버는 대형 모델과 오케스트레이션
ㅇ 디바이스는 즉시 반응하는 개인화 추론
QNN은
Snapdragon을 단순한 모바일 칩이 아니라
퍼스널 AI 컴퓨팅 노드로 만드는 핵심 레이어라고 볼 수 있다.
ㅁ 마무리
흥미로운 점은, 이런 구조를 처음 접한 계기가 순수한 AI 개발이 아니라
오픈소스 라이선스 검증과 SDK 구조 분석이었다는 것이다.
라이선스를 따라가다 보니 런타임 구조가 보였고,
구조를 따라가다 보니 Snapdragon 생태계의 방향성이 보이기 시작했다. ^^
QNN은 프레임워크가 아니다.
가상화도 아니다.
Snapdragon SoC 전체를 하나의 AI 실행 환경으로 묶는
추론 전용 런타임 플랫폼이다.
JVM 개발자 관점에서는 이렇게 이해하면 가장 빠르다.
한마디로,
QNN은 Snapdragon NPU를 위한 AI JVM이다.
'AI > AI플랫폼 | 서비스' 카테고리의 다른 글
| [Kakao i] AI Service Agent란? (2) | 2025.05.29 |
|---|---|
| [AI] VESSL AI란? (0) | 2025.05.02 |

