
- 분류 전체보기 (976)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Spring
- kotlin
- Kubernetes
- 바이브코딩
- PETERICA
- Rag
- aws
- 오블완
- 코틀린 코루틴의 정석
- MySQL
- golang
- 기록으로 실력을 쌓자
- AWS EKS
- Linux
- tucker의 go 언어 프로그래밍
- CKA 기출문제
- 공부
- Java
- Pinpoint
- CKA
- APM
- go
- AI
- 티스토리챌린지
- SRE
- LLM
- minikube
- kotlin coroutine
- CloudWatch
- 정보처리기사 실기 기출문제
- Today
- Total
피터의 개발이야기
[DevOps 모니터링] 서비스 퍼포먼스를 위한 응답 시간 체크 방법 본문

ㅁ 개요
ㅇ 대량 트레픽 서비스에서 퍼포먼스 향상을 위해서는 트레픽의 응답 시간 체크가 필수적이다.
ㅇ 응답이 지연되는 프로세스를 체크하고 퍼포먼스를 향상함으로써 제한된 리소스에서 서비스의 TPS를 높여 고가용성을 얻을 수 있다.
ㅇ 고가용성을 높인가는 것은 적은 리소스로 더 많은 요청을 처리하게 되면서 AWS 비용절감과 시스템 병목장애를 예방할 수 있다.
ㅇ 그러므로 트레픽 응답 지연 모니터링은 DevOps의 필수적인 요소이다.
ㅁ AWS 대상그룹의 대상 응답시간 지표
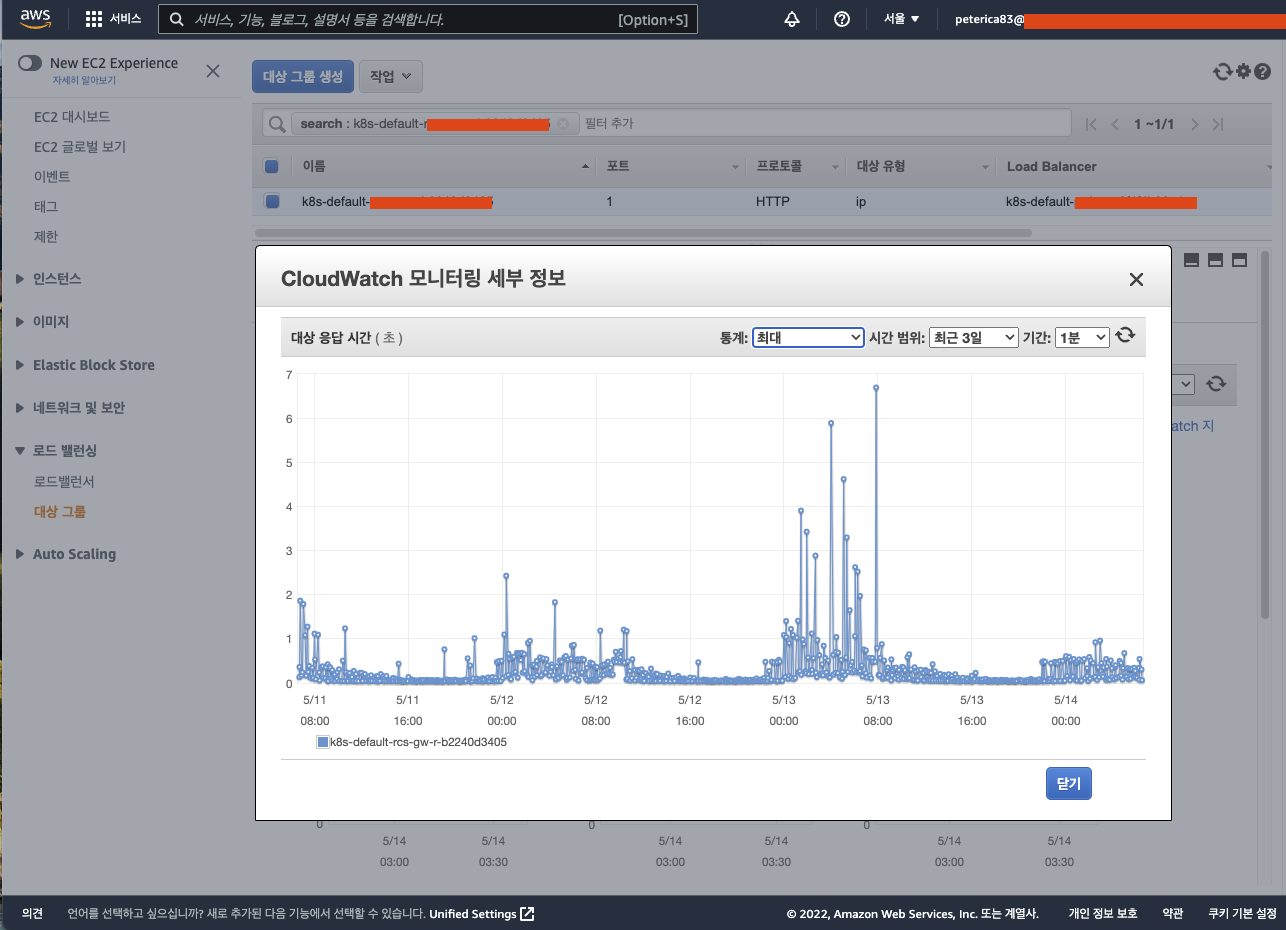
ㅇ 대부분의 트래픽이 1초 미만인 것을 확인 할 수 있다. 하지만 특정 트래픽은 1초 이상의 것이 확인되고 있다.

ㅇ Cloud Watch에 8초 이상에 대해서는 경고를 설정해 두었다.
ㅇ 이미지의 상태를 보면 0.053초 이하로 정상적인 상태임을 알 수 있다.
ㅇ AWS의 지표는 대상그룹의 in out 시간을 체크하기 때문에 그 트래픽의 상세정보는 찾기 어려운 부분이 있다.
그래서 APM 도구가 필요하며, 현재 Whatap을 사용하고 있다.
ㅁ Whatap을 이용한 트래픽 지연 분석
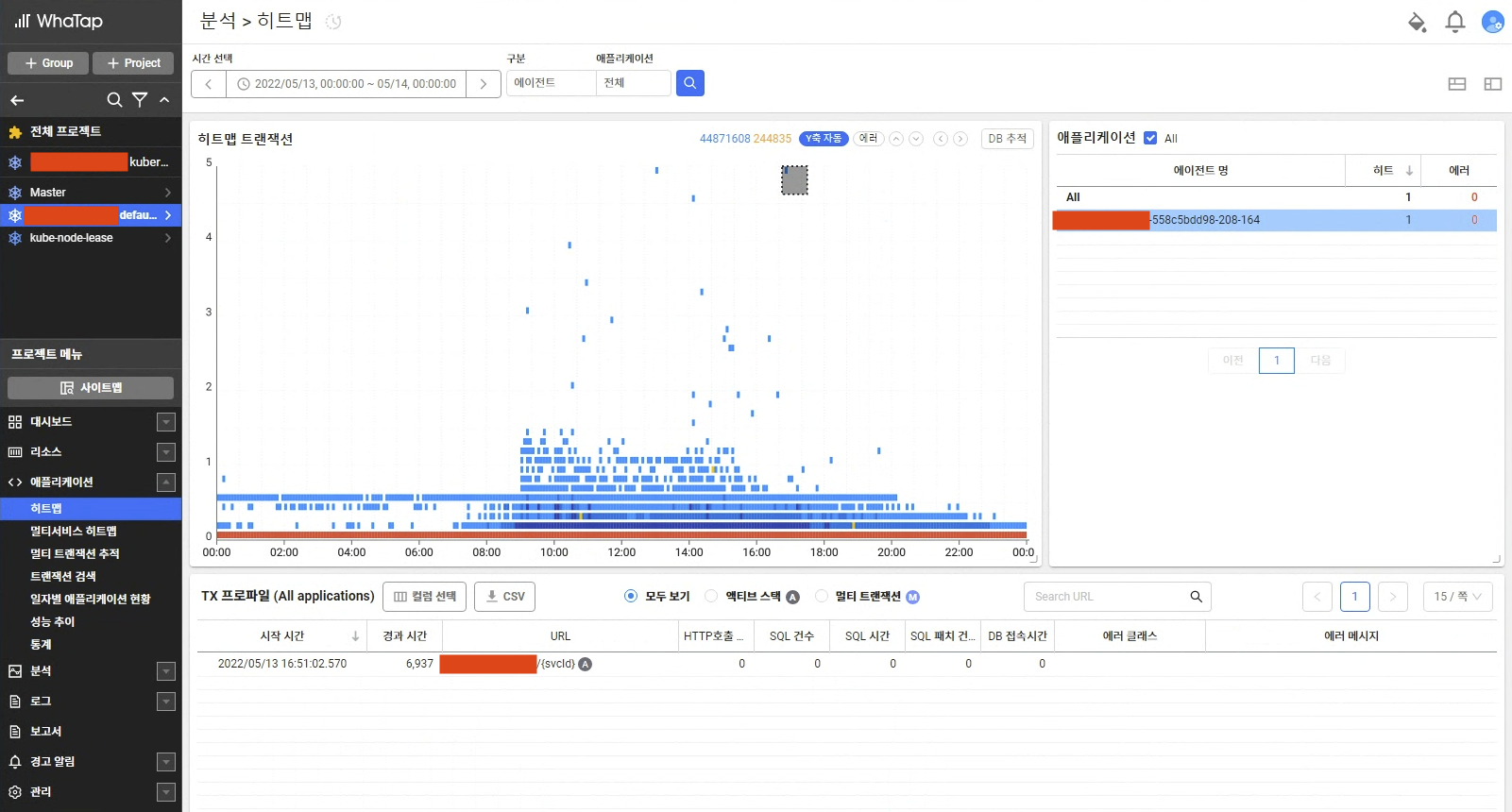
ㅇ 히트맵 상에서 지연된 트렌젝션을 드레그했을 때에 트렌젝션의 상세 목록이 아래의 표에 나타난다.
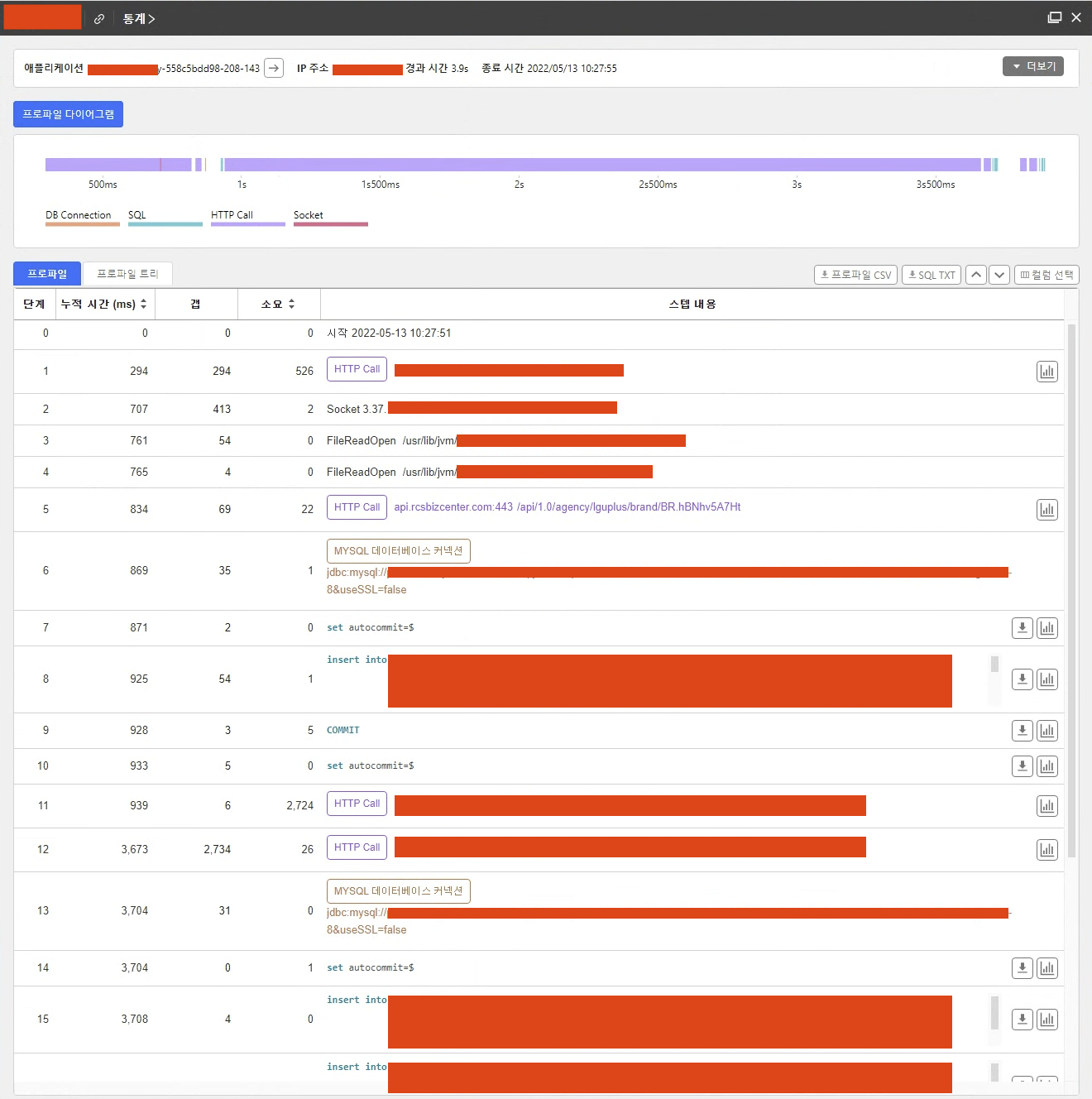
ㅇ 목록을 클릭하면 트레픽의 세부적인 프로세스를 확인할 수 있다.
ㅇ SQL, HTTP Call, DB SQL 등을 확인할 수 있다.
ㅇ 프로세스의 세부적인 갭을 확인하여 지연되는 특정 구간을 확인 할 수 있다.
ㅇ 이 트렌젝션의 경우 HTTP Call이 상당한 시간을 차지하고 있다.
ㅁ TraceFilter를 이용한 트래픽 소요시간 확인

ㅇ TraceFilter에 request 시작과 끝의 시간을 elapsed_time으로 표시하고 있다.

ㅇ filter의 코딩이다. 필터가 시작할 때의 시간을 기록하고 요청이 소멸되었을 때에 걸리는 시간을 기록하고 있다.
ㅇ 로그 점검 시 빠른 검색을 위해서 특정시간 이상으로 지연될 경우 로그에 특정 패턴을 추가하는 것도 좋은 방법이 될 수 있다.
'DevOps' 카테고리의 다른 글
| [AWS] AutoScale ShutDown 시간 연장하기 (0) | 2022.05.23 |
|---|---|
| [AWS] RDS Aurora 성능 증감 시 작업 과정 정리, fail over 처리 (0) | 2022.05.17 |
| [AWS] Amazon EKS 쿠버네티스 버전 확인 (0) | 2022.05.13 |
| [docker]Failed to get D-Bus connection 에러 해결 (0) | 2021.02.09 |
| [docker] CentOS 7 설치하기 (0) | 2021.02.07 |



