
- 분류 전체보기 (859)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 코틀린 코루틴의 정석
- kotlin coroutine
- Java
- Pinpoint
- Elasticsearch
- mysql 튜닝
- go
- 정보처리기사실기 기출문제
- AI
- Kubernetes
- docker
- 정보처리기사 실기 기출문제
- 오블완
- minikube
- 기록으로 실력을 쌓자
- Spring
- CKA 기출문제
- 티스토리챌린지
- Linux
- tucker의 go 언어 프로그래밍
- aws
- kotlin
- kotlin querydsl
- 공부
- CKA
- CloudWatch
- PETERICA
- golang
- AWS EKS
- APM
- Today
- Total
피터의 개발이야기
[kubernetes network] CNI란? 본문
ㅁ 개요
ㅇ 지난 글에서 EKS CNI 플러그 트러블슈팅을 정리하면서 CNI 대해 궁금한 점이 생겼다.
ㅇ 공부를 위한 개념정리 차원에서 글을 작성하였으며, 아래의 참조 블러그 내용 중에서 필요한 부분을 취합 정리하였다.
ㅁ CNI란 무엇인가?
Linux 컨테이너에서 네트워크 인터페이스를 구성하기 위한 플러그인
CNI 공식 GitHub에 따르면, Cloud Native Computing Foundation 프로젝트인 CNI(Container Network Interface)는 컨테이너 간의 네트워킹을 제어할 수 있는 기술적인 표준이다. Linux의 애플리케이션 컨테이너가 빠르게 발전하면서 기술적인 통일성을 확립하였지만, 다양한 형태로 컨테이너 런타임과 오케스트레이터 사이의 네트워크 계층을 구현하면서 중복된 문제를 다양한 형태로 만들기 시작하였다. 이를 피하기 위해 공통된 인터페이스를 통한 기술적 표준의 확립이 필요하였다. 컨테이너 런타임과 오케스트레이터가 네트워크 계층을 플러그로 가능하게 만들기 위해서 CNI는 컨테이너의 네트워크 연결과 컨테이너가 삭제될 때 할당된 리소스를 제거하는 데에 집중하였다. 쿠버네티스에서는 Pod 간의 통신을 위해서 CNI 를 사용하였다.
쿠버네티스 뿐만 아니라 Amazon ECS, Cloud Foundry 등 컨테이너 런타임을 포함하고 있는 다양한 플랫폼들은 CNI를 사용하고 있다. 쿠버네티스는 기본적으로 'kubenet' 이라는 자체적인 CNI 플러그인을 제공하지만 네트워크 기능이 매우 제한적인 단점이 있다. 그 단점을 보완하기 위해, 3rd-party 플러그인을 사용하는데 그 종류에는 Flannel, Calico, Weavenet, NSX 등 다양한 종류의 3rd-party CNI 플러그인들이 존재한다.
ㅁ CNI 플러그인 용어
CNI는 표준으로써의 인터페이스의 역할을 할 뿐, 특정 서비스에 적용하기 위해서는 인터페이스를 구체화하여 자신의 서비스에 맞추어 적용해야 한다. CNI문서에서는 이를 3rd party plugins, 쿠버네티스 문서에서는 network plugin, 또 다른 문서들에서는 cni network providers 혹은 단순하게 cni 로 지징하기도 한다. AWS에서는 CNI의 추가기능을 EKS에 쉽게 적용할 수 있도록 해주고 있기에 Plugin의 형태를 띄고 있다. 그래서 나에겐 CNI plugin이라 명칭하는 것이 바람직하게 보인다.
ㅁ CNI 플러그인을 왜 써야하나?
서드파티 CNI들이 제공하는 다양한 기능들(Network Policy, Public 클라우드와의 통합, 대규모 트래픽에 대한 안정성 등)의 장점을 활용하기 위해서 사용할 수도 있지만, 가장 큰 이유는 기본제공되는 kubenet 그 자체로는 컨테이너간의 노드간 교차 네트워킹조자 지원하지 않기 때문이다.
예를들어, 쿠버네티스 오케스트레이션 환경에서 여러 WorkNode에 Docker 기반 컨테이터가 운영된다고 가정해보자. 컨테이너는 서로 간에 통신이 필요할 것이다. WorkNode A에서 WorkNode B로 트래픽을 보내기 위해서는 출발 컨테이너 eni를 통해 docker의 브릿지 인터페이스를 타고 NAT처리 되어 WorkNode A의 물리 인터페이스인 ens으로 나간다. 그 후, WorkNode B의 물리 인터페이스로 들어와 docker의 브릿지 인터페이스를 통해 대상 컨테이너로 들어온다.
만약, 두 컨테이너의 IP대역이 동일하게 되면 동일 아이피로 인해 다른 컨테이너로 통신을 시도할 때에 자기 자신인 컨테이너로 통신을 하게 시도 할 것입니다. 위와 같은 멀티 호스트로 구성되어 있는 컨테이너 끼리 통신을 하기 위해서는 CNI가 반드시 필요하다.
ㅁ CNI 플러그인의 네트워크 모델
1. 오버레이 네트워크(Overlay Network)
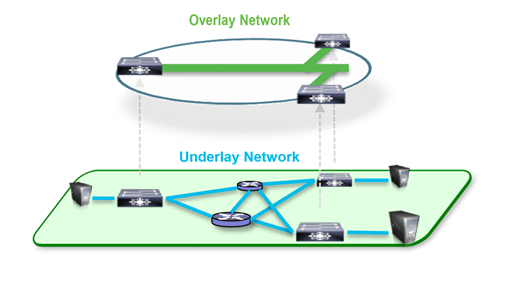
오버레이 네트워크는 3계층을 넘어서 구축된 네트워크 간에 있는 엔드포인트의 노드간의 통신이 일어날때 패킷을 한겹 캡슐화 하여 통신시켜서, 2계층에서(같은 LAN에서) 통신이 일어나는 것처럼 통신할 수 있도록 하는 기술이다. 기본 개념은 실제로는 복잡할 수 있는 엔드포인트 간의 네트워크 구조를 추상화하여 네트워크 통신 경로를 단순화 하는 것이다.
Overlay Network는 기본적으로 ①패킷을 encapsulation 해서 통신 노드간에 가상 Tunnel을 이용하여 ②캡슐화 된 패킷을 전달하는 방식을 활용하여 복잡한 네트워크 환경에서의 통신을 추상화 한다.
오버레이 네트워크를 사용하면 거의 대부분의 환경에서 기존 네트워크 환경에 영향 없이 CNI 환경을 구성할 수 있지만, 패킷을 캡슐화 할때 CPU 등의 자원도 소모하고 패킷의 전체 크기에서 캡슐화를 위해 사용하는 영역 만큼 패킷 당 송/수신 할 수 있는 데이터의 양이 줄어들어 상대적으로 비효율적인 단점도 있다.
2. BGP 기반 네트워크
BPG 기반의 오버레이는 통신이 발생하는 노드간에 bgp 프로토콜을 사용하는 소프트웨어 라우터의 구현을 통해서 최적의 경로 정보를 현재 엔드포인트들의 상태를 따라서 동적으로 감지하여 적용할 수 있다는 전제를 통해 구현되는 네트워크 모델이다.
BGP 프로토콜을 사용하여 CNI를 구성하면, HA를 위해 클러스터 구성 노드들간의 서브넷이 다르게 구성되어 있는 경우 상위의 물리 라우터에도 별도의 설정을 해주어야 하고, 통신이 가능한 대역에서 여러 클러스터를 활용하거나 별도의 외부 서비스들을 운영하는 경우 네트워크 대역이 겹치지 않도록 관리를 해주어야 하고, 그렇기 때문에 퍼블릭 클라우드에서 구성이 자유롭지 않은 단점이 있다.
하지만 별도의 패킷 가상화 없이 기존에 네트워크에서 사용하던 직관적인 라우팅 방식을 이용함으로써 클러스터 외부에서도 Ingress나 Service의 도움 없이 POD에 접근 할 수 있게 되고, 통일화 된 보안 설정 관리 및 디버깅/로깅의 용이성과 더불어 오버레이 네트워크에 비해 성능이 좋다는 구분되는 장점도 분명하게 존재한다.
ㅁ CNI에서 Overlay Network vs BGP 네트워크 모델 요약
두 네트워크 모델 중에서는 BGP기반의 모델이 성능적으로 더 빠르고 안정적인 모습을 보여준다. 패킷에 대한 캡슐/복호화 과정에서 발생하는 오버헤드가 없기 때문이다. 하지만, BGP기반의 방식은 노드간의 서브넷이 다를 경우 물리적인 라우터 장비의 설정을 변경해주어야 하는 환경 의존성이 분명하게 존재하고, 이 단점은 특히 퍼블릭 클라우드에서 쿠버네티스 환경을 구성할 때 치명적인 단점이 된다. 따라서, 본인의 클러스터를 구성하는 환경에 따라서 적절한 네트워크 모델을 선택하여 적용하는 것이 바람직하다.
ㅁ 참조 사이트
k8s의 CNI란
Kubernetes를 설치하여 사용할때 항상 CNI를 설치해야 core-DNS서비스가 정상동작하고, 네트워크 폴리시 등의 보안 정책을 적용할 수 있었기에, 그냥 무의식적으로 설치하여 사용했었는데 막상 다시
tommypagy.tistory.com
[#1. Kubernetes 시리즈] 3. CNI란? (Container Network Interface)
이번 글에서는 쿠버네티스를 설치하기 전에 간략하게 CNI(Container Network Interface)에 대하여 알아보겠습니다. 무작정 문서대로 설치만 하기 보다는 내가 설치하는 애가 무엇인지 알고 가는게 좋을
captcha.tistory.com
Calico?Weave? CNI에 관하여
Kubernetes를 설치하여 사용할때 항상 CNI를 설치해야 core-DNS서비스가 정상동작하고, 네트워크 폴리시 등의 보안 정책을 적용할 수 있었기에, 그냥 무의식적으로 설치하여 사용했었는데 막상 다시
ykarma1996.tistory.com
GitHub - containernetworking/cni: Container Network Interface - networking for Linux containers
Container Network Interface - networking for Linux containers - GitHub - containernetworking/cni: Container Network Interface - networking for Linux containers
github.com
클러스터 네트워킹
네트워킹은 쿠버네티스의 중심적인 부분이지만, 어떻게 작동하는지 정확하게 이해하기가 어려울 수 있다. 쿠버네티스에는 4가지 대응해야 할 네트워킹 문제가 있다. 고도로 결합된 컨테이너 간
kubernetes.io

'Kubernetes > network' 카테고리의 다른 글
| Ingress-Nginx로 HTTP가 아닌TCP나 UDP 트래픽 노출하기 (1) | 2024.11.18 |
|---|---|
| [Network] ICMP: 인터넷의 숨은 영웅 (0) | 2024.11.16 |
| [kubernetes] network 테스트 방법 (0) | 2024.01.21 |
| NAT란, Bridged Networking란, Virtual Network란? (0) | 2024.01.14 |

