
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- Elasticsearch
- minikube
- Kubernetes
- CKA 기출문제
- kotlin querydsl
- Spring
- 티스토리챌린지
- 정보처리기사 실기 기출문제
- 오블완
- 기록으로 실력을 쌓자
- Linux
- AI
- Java
- tucker의 go 언어 프로그래밍
- 코틀린 코루틴의 정석
- AWS EKS
- CloudWatch
- PETERICA
- APM
- docker
- 정보처리기사실기 기출문제
- Pinpoint
- 공부
- kotlin
- mysql 튜닝
- go
- CKA
- aws
- kotlin coroutine
- golang
Archives
- Today
- Total
피터의 개발이야기
[MySQL] 대용량 샘플 데이터 사용하기 본문
반응형

ㅁ 개요
MySQL을 공부하면서 대용량 샘플 데이터가 필요할 때가 있습니다. 이를 위해 MySQL 홈페이지에서 샘플데이터를 제공합니다. 이번 글에서는 샘플데이터의 종류와 설치 방법에 대해서 정리해 보았습니다.
ㅁ Example Databases
| Title | DB Download | Guide Page | |
| employee data (large dataset, includes data and test/verification suite) | GitHub | View | US Ltr | A4 |
| world database | TGZ | Zip | View | US Ltr | A4 |
| world_x database | TGZ | Zip | View | US Ltr | A4 |
| sakila database | TGZ | Zip | View | US Ltr | A4 |
| airportdb database (large dataset, intended for MySQL on OCI and HeatWave) | TGZ | Zip | View | US Ltr | A4 |
| menagerie database | TGZ | Zip |
ㅁ Employee Data 소개
직원 샘플 데이터베이스는 6개의 개별 테이블에 분산되어 있고 총 4백만 개의 레코드로 구성된 방대한 데이터(약 160MB)를 제공합니다.
ㅁ Employee Data SQL 다운로드
$ git clone https://github.com/datacharmer/test_db.git
Cloning into 'test_db'...
remote: Enumerating objects: 120, done.
remote: Total 120 (delta 0), reused 0 (delta 0), pack-reused 120
Receiving objects: 100% (120/120), 74.27 MiB | 20.11 MiB/s, done.
Resolving deltas: 100% (62/62), done.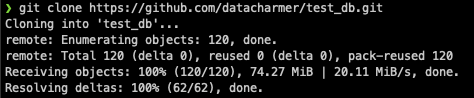
직원 데이터베이스는 GitHub의 직원 DB 에서 git clone을 하였습니다.
ㅁ Table과 View 생성

ㅇ Intellij에서 MySQL DB를 선택하고 SQL Scripts > Run SQL Script... 를 선택합니다.
ㅇ employees.sql를 실행하면 6개의 테이블이 생성 됩니다.
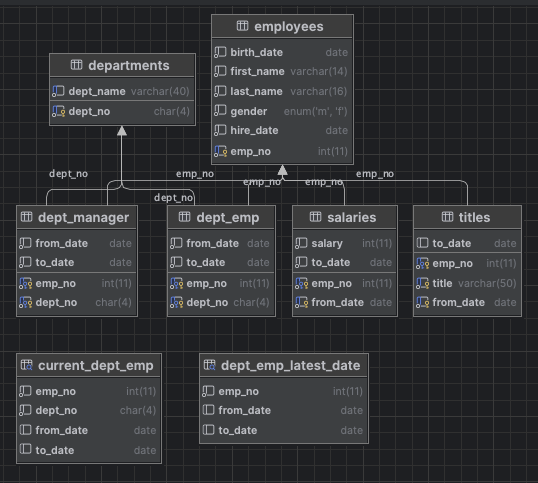
ㅇ 테이블만 생성되었고, 데이터는 없는 상태입니다.
ㅁ Dump Script 실행
$ head -10 load_employees.dump
INSERT INTO `employees` VALUES (10001,'1953-09-02','Georgi','Facello','M','1986-06-26'),
(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21'),
(10003,'1959-12-03','Parto','Bamford','M','1986-08-28'),
(10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01'),
(10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12'),
(10006,'1953-04-20','Anneke','Preusig','F','1989-06-02'),
(10007,'1957-05-23','Tzvetan','Zielinski','F','1989-02-10'),
(10008,'1958-02-19','Saniya','Kalloufi','M','1994-09-15'),
(10009,'1952-04-19','Sumant','Peac','F','1985-02-18'),
(10010,'1963-06-01','Duangkaew','Piveteau','F','1989-08-24'),ㅇ Dump 파일을 확인해 보면 Insert SQL문이 들어 있습니다.
ㅇ 위에서 했던 Script 실행 방법과 동일하게 dump 파일을 실행하였습니다.
load_departments.dump
load_employees.dump
load_titles.dump
load_dept_emp.dump
load_dept_manager.dump
load_salaries1.dump
load_salaries2.dump
load_salaries3.dumpㅇ 테이블 간의 의존성 때문에 위의 dump 순서대로 스크립트를 실행하였습니다.
[2023-08-18 11:08:37] Connecting to @peterica.iptime.org… (employees)
[2023-08-18 11:08:37] Using batch mode, maximum number of INSERT/UPDATE/DELETE statements is 1000
[2023-08-18 11:08:37] Run /Users/peterica.seo/study/test_db/load_salaries1.dump
INSERT INTO `salaries` VALUES (10001,60117,'1986-06-26','1987-06-26'),
(10001,62102,'1987-06-26','1988-06-25'),
(10001,66074,'1988-06-25','1989-06-25'),
(10001,66596,'1989-06-25','1990-06-25'),
(10001,66961,'1990-06-25','1991-06-25'),
(1000...
[2023-08-18 11:08:39] 24953 row(s) affected in 1 sec, 416 ms
.
[2023-08-18 11:08:42] 26100 row(s) affected in 1 sec, 630 msㅇ Intellij에서 스크립트 실행 시 실행 예시입니다.
ㅁ Test Data 등록 확인
SELECT TABLE_NAME, DATA_LENGTH
FROM information_schema.tables
WHERE TABLE_SCHEMA='employees'
ORDER BY 2 DESC;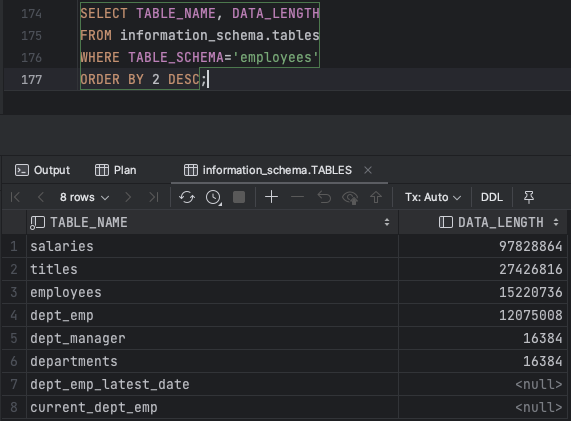
ㅁ 함께 보면 좋은 사이트
반응형
'Database > MySQL' 카테고리의 다른 글
| [MySQL] Mysql Docker 설치, 8.0 (0) | 2023.08.22 |
|---|---|
| [MySQL] DB 용량 확인, 테이블별 용량 확인 (3) | 2023.08.18 |
| [MySQL] 참고자료 목록 (0) | 2023.08.11 |
| [MySQL 튜닝] INSTR, LIKE, LOCATE, REGEXP 검색 속도 비교 (0) | 2023.08.10 |
| [MySQL] MySQL DB에서 Select 쿼리가 늦어지는 이유 (0) | 2023.08.02 |
'Database/MySQL' Related Articles
more




Comments