
- 분류 전체보기 (1002)

Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- kotlin
- go
- 기록으로 실력을 쌓자
- 바이브코딩
- Spring
- 티스토리챌린지
- SRE
- CloudWatch
- kotlin coroutine
- 정보처리기사 실기 기출문제
- CKA
- AWS EKS
- 공부
- MySQL
- golang
- aws
- PETERICA
- Java
- Claude
- HARNESS
- docker
- 코틀린 코루틴의 정석
- 오블완
- Kubernetes
- CKA 기출문제
- tucker의 go 언어 프로그래밍
- minikube
- AI
- LLM
- Rag
Archives
- Today
- Total
피터의 개발이야기
[AI] AI 학습과 추론, HBM과 GDDR의 차이점 본문
반응형

ㅁ 들어가며
HBM(High Bandwidth Memory, 고대역폭 메모리)은 AI 모델 학습에,
GDDR(Graphics Double Data Rate, 그래픽스 전용 메모리)은 AI 추론에 각각 최적화된 메모리로 볼 수 있습니다.
AI 학습에는 왜 HBM이 유리할까? 🧠
AI, 특히 LLM(대규모 언어 모델, Large Language Model)처럼 방대한 데이터를 다루는 딥러닝 학습 과정에서는
GPU가 잠시도 기다리지 않도록 극도로 높은 메모리 대역폭(Bandwidth)이 필요합니다.
모델의 가중치, 활성화값(activation), 그리고 기울기(gradient) 등 엄청난 데이터가 반복적으로 오고 갑니다.
HBM의 주요 장점
- 압도적인 대역폭
HBM2e를 탑재한 NVIDIA A100 GPU: 최대 2TB/s 제공
HBM3를 사용한 NVIDIA H100: 최대 3.35TB/s 지원- 3D 스태킹 아키텍처(3D stacking, 여러 DRAM 다이를 수직 적층)와
TSV(Through-Silicon Via, 실리콘 관통 전극) 구조로
넓은 병렬 데이터 통로와 고속 데이터 전송을 실현함
- 3D 스태킹 아키텍처(3D stacking, 여러 DRAM 다이를 수직 적층)와
- 큰 메모리 용량
예: NVIDIA H100의 HBM 용량 80GB- 3D 스태킹 구조 덕분에 작은 공간에 다수의 메모리 칩 적층 가능
- 파라미터 수십억 개인 대형 모델 학습 시 유리
- 전력 효율
TSV 구조로 데이터가 짧은 거리 이동 → 비트당 에너지 소모 감소- 대규모 클러스터, 데이터센터에 필수 요소
- 메모리 병목 현상 완화
높은 대역폭·용량 덕분에 GPU가 메모리 병목 없이 학습 가능- Google TPU v4, NVIDIA H100 등 최신 고성능 AI 학습용 칩셋 다수 적용
AI 추론에는 왜 GDDR이 적합할까? 💡
AI 추론은 이미 학습된 모델로 새로운 입력에 대해 예측/판단하는 과정입니다.
빠른 데이터 접근은 중요하지만, 학습만큼 극한의 대역폭은 필요치 않습니다.
GDDR의 주요 장점
- 충분히 높은 대역폭
예:- GDDR6을 탑재한 NVIDIA RTX A6000: 약 768GB/s
- AMD Radeon RX 7900 XTX(GDDR6): 960GB/s
- 메모리 접근 빈도와 데이터 이동량이 학습보다 적어 충분
- 비용 효율성
GDDR6/7은 대량 생산 및 성숙한 공정으로 단가가 저렴- 서버, PC, AI 엣지 디바이스에 널리 채택
- 설계 및 통합 용이성
- 표준화와 높은 호환성으로 빠른 개발·양산에 유리
- 낮은 지연 시간(Latency)
실시간 응답 필요한 서비스(예: 자율주행, 실시간 비전)에 적합- NVIDIA GeForce RTX 40 시리즈, AMD Radeon RX 7000 시리즈 등 다양한 GPU에 활용
한눈에 보는 정리
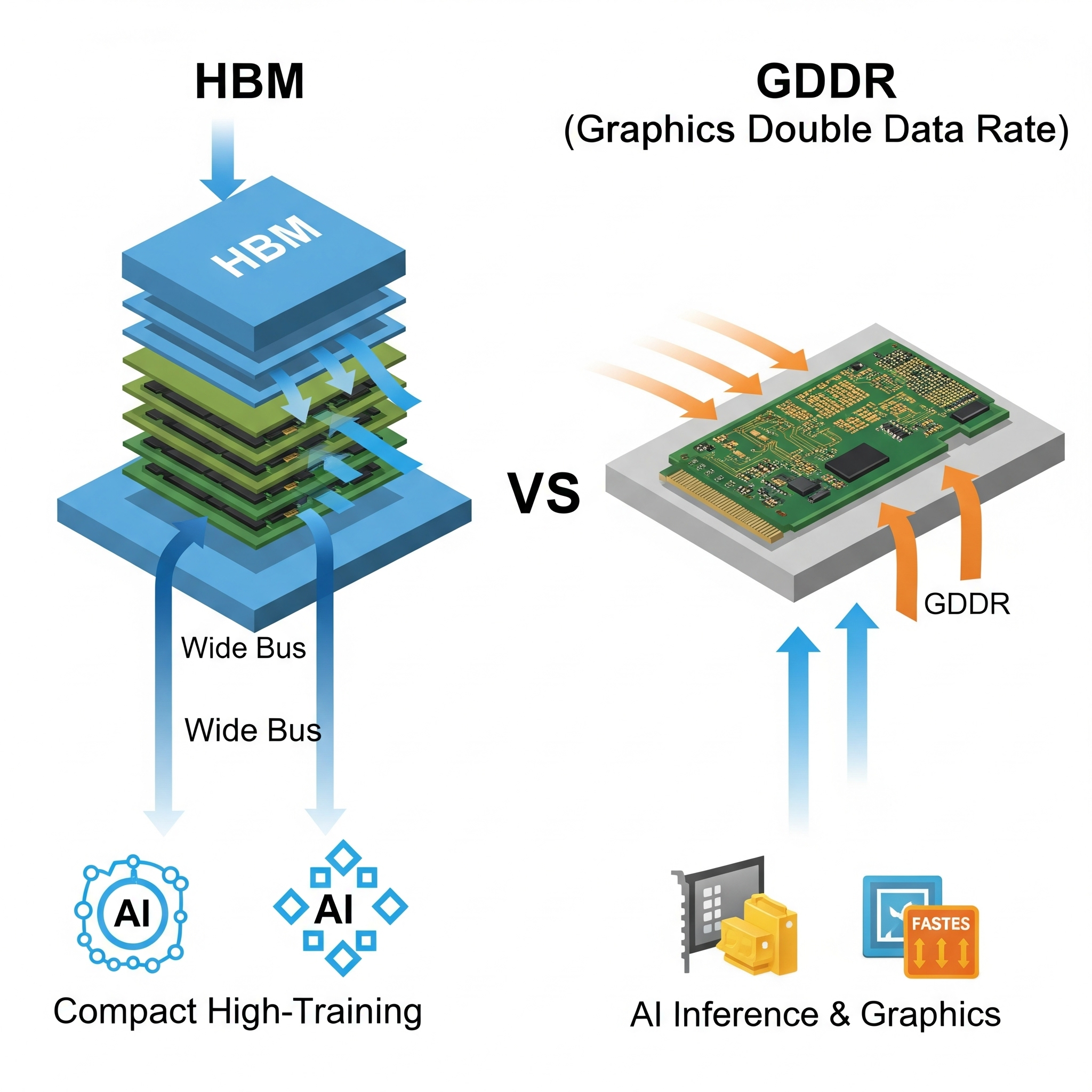

- HBM:
- 대역폭과 용량이 크고, 전력 효율이 뛰어나다
- 대규모·고난도 AI 학습에 최적
- GDDR:
- 충분한 대역폭, 저렴한 가격, 낮은 지연
- 대규모 배포·비용·실시간성이 중요한 AI 추론에 적합
용어 설명
| 용어 | 설명 |
| HBM (High Bandwidth Memory) |
여러 DRAM 칩을 수직으로 적층(3D stacking)하여 TSV(Through-Silicon Via, 실리콘 관통 전극)로 연결, 고대역폭·고용량·저전력 실현
|
| GDDR (Graphics Double Data Rate) |
그래픽 카드 및 고속 데이터 처리용으로 개발된 DRAM 계열 메모리, PCB(회로 기판) 위에 칩을 배치하는 2D 구조
|
| 3D 스태킹(적층) |
DRAM 칩들을 수직으로 차곡차곡 쌓아 올려 공간 효율과 성능을 동시에 높이는 기술
|
| TSV (Through-Silicon Via) |
실리콘 기판을 관통하는 수직 전극, 칩 간의 초고속·저지연 데이터 전송 실현
|
| 대역폭(Bandwidth) |
단위 시간당 데이터 전송 가능한 양. 값이 높을수록 데이터 병목 현상 최소화
|
| 지연 시간(Latency) |
요청 후 응답까지 걸리는 시간. 값이 낮을수록 실시간성에 유리
|
대표 제품·서비스 예시
| 용도 | 대표 메모리 | 대표 제품/서비스 |
| AI 학습 | HBM2e, HBM3 |
NVIDIA H100, A100, Google TPU v4, AMD MI300
|
| AI 추론 | GDDR6, GDDR6X, GDDR7 |
NVIDIA RTX A6000, RTX 4090, AMD RX 7900 XTX, 다양한 AI 엣지 서버
|
마무리
대규모 복잡한 AI 모델의 학습에는 HBM,
다양한 환경에 AI 추론을 배포하려면 GDDR!
상황에 맞는 메모리 선택이,
AI의 성능과 비용, 그리고 에너지 효율을 좌우합니다.
관련 기사
반응형
'AI > AI산업 | 동향' 카테고리의 다른 글
| 백엔드 개발자가 정리한 PIM vs PNM: 메모리 근처에서 연산한다는 것의 진짜 의미 (0) | 2025.12.03 |
|---|---|
| [AI] 카카오 국가대표AI 탈락 이유 분석 (2) | 2025.08.05 |
| [AI] DeepSeek: AI 산업의 새로운 패러다임을 제시하는 혁신적인 중국 스타트업 (2) | 2025.01.30 |
| [AI] 슬라이딩 강유전: 메모리 기술의 새로운 지평 (0) | 2024.11.12 |
| [AI] 생성형 AI의 미래 산업, 검색의 시대에 대화의 시대, Business AI Agent란 (2) | 2024.09.25 |
'AI/AI산업 | 동향' Related Articles
more

Comments