
- 분류 전체보기 (1007)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- AI
- Claude
- 오블완
- CloudWatch
- MySQL
- 바이브코딩
- SRE
- Spring
- PETERICA
- HARNESS
- 티스토리챌린지
- tucker의 go 언어 프로그래밍
- CKA
- 코틀린 코루틴의 정석
- kotlin
- minikube
- 정보처리기사 실기 기출문제
- AWS EKS
- aws
- Java
- docker
- golang
- Rag
- Kubernetes
- kotlin coroutine
- 기록으로 실력을 쌓자
- go
- LLM
- CKA 기출문제
- 공부
- Today
- Total
피터의 개발이야기
[AI] Cursor 토큰 소비 구조와 절약 전략 (실사용 경험 기반) 본문

ㅁ 들어가며
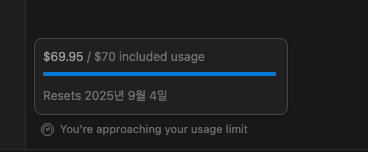
최근 바이브코딩을 통해 기존 코드의 고도화, 2개의 gateway를 하나로 통합, 신규 모니터링 알람 프로젝트를 진행하였다. 토큰이 부족하여 20$, 60$(8.4)를 지불하였지만, 8.8에 모든 토큰을 소모하고 말았다. 이번 글에서는 토큰은 무엇인지, 토큰 소비에 구조와 절약 전략을 정리해 보았다.
ㅁ 토큰이란 무엇인가?
토큰은 AI 모델이 텍스트를 처리하는 최소 단위이다.
영어 단어 하나는 보통 1~2 토큰, 한국어 단어 하나는 2~3 토큰 정도로 계산된다.
Cursor에서 한 번 요청을 보내면 내가 작성한 프롬프트 + 모델이 참고하는 컨텍스트(이전 대화, 코드, 분석 대상 파일)가 모두 토큰으로 환산된다.
ㅁ Cusrsor 요금제 변경
| 요금제 | 특징 |
| Pro ($20/mo) |
Auto 모드에서 무제한 사용 가능
직접 모델 선택 시 월 $20 크레딧 사용 후 추가 과금 발생 |
| Ultra ($200/mo) |
Pro 대비 20배 더 많은 사용량 제공
고정 요금으로 예측 가능성이 높음 |
ㅇ Pro 요금제: 요청 기반 → 사용량 기반 과금 전환
- 이전 방식: 월 500회 요청(“빠른 요청”) 제공, 이후엔 속도는 느리지만 무제한 응답 제공
- 변경 이후 (6월 16일 시행): 이제 Pro 요금제는 ‘월 $20 상당의 AI 모델 사용량 크레딧’을 제공하고, 이 크레딧을 초과하면 추가 과금이 발생(나는 추가 과금 옵션 OFF 상태)
- 대부분 사용자에게 이 크레딧은 Sonnet 4 기준 약 225회, Gemini 약 550회, GPT‑4.1 기준 약 650회의 요청에 해당하는 수준으로 충분하다고 한다.
ㅇ Auto 모드: 무제한 사용
- Pro 플랜에서 Auto 모드(모델 자동 선별)를 선택하면, 이 모드 내에서는 모델 사용이 무제한으로 제공된다.
- 하지만 직접 특정 모델을 선택할 경우에는 여전히 $20 크레딧 한도 내에서만 사용 가능합니다.
ㅁ Cursor에서 토큰이 소비되는 주요 시점
ㅇ 프로젝트 전체 분석 시 폭발
- 8월 4일에 Prism-lab과 Sentinel 프로젝트를 동시에 분석했는데, 하루에 약 1억 토큰을 사용했다.
- 원인은
전체 폴더 분석명령어로 수천 개의 코드 라인을 한 번에 전달했기 때문이었다.
ㅇ 대화가 길어질수록 기하급수 증가
- 장시간 같은 세션에서 작업하면 이전 대화 내용이 계속 포함되어 토큰 소모가 급증했다.
- 단순 코드 수정 요청임에도 불구하고, 이미 누적된 대화 기록 때문에 2~3배 더 소비됐다.
ㅇ 자동완성(Auto-complete) 기능의 은근한 소모
- 커서에서 코드를 작성할 때 자동완성이 켜져 있으면, 매 입력 시 주변 코드 맥락이 전송된다.
- 짧은 함수 수정이라도 주변 코드 덩치가 크면 토큰 소모가 수백~수천까지 올라간다.
ㅇ MCP(Model Context Protocol) 사용 시 스키마·도구 응답 전송
- MCP를 사용할 때 도구 스키마, 함수 정의, 인자 예시, 실행 결과(JSON)가 프롬프트에 포함되면서 토큰 소모가 커진다.
- 특히 여러 MCP 도구를 동시에 로드하거나 반복 호출하면 호출 수 × 응답 크기만큼 토큰이 누적된다.
ㅁ MCP의 토큰 소비는?
ㅇ MCP(Model Context Protocol)
- 영향: 도구 스키마, 함수 목록, 인자 예시, 도구 응답(JSON)까지 프롬프트에 실리면 입력 토큰이 급증한다. 도구를 여러 번 왕복 호출하면 호출 수 × 응답 크기만큼 누적된다.
- 절약 팁: 필요한 도구만 로드한다 → 스키마를 축소한다 → 쿼리 결과는 페이징·필드 선택으로 최소화한다 → 로그·스택트레이스는 링크만 남기고 전문은 붙이지 않는다.
ㅇ Context7(대화 맥락 확장/메모리 계열 기능)
- 영향: 장문의 과거 대화 요약·메모가 자동 주입되면 매 요청마다 숨은 프리앰블이 따라붙어 입력 토큰이 늘어난다. 컨텍스트 윈도우가 크면 “더 보낼 수 있음=더 보낸다”로 이어진다.
- 절약 팁: 세션을 주제별로 분리한다 → 고정 브리프를 짧게 만들어 ‘핀’으로 쓰고, 과거 전문은 링크나 작은 요약으로 대체한다 → 큰 파일은 참조 경로만 넘기고 본문은 필요 시에만 불러온다.
ㅇ Sequential Thinking(체계적 단계 사고 모드)
- 영향: “단계별로 설명하라”“사고 과정을 써라” 같은 지시는 출력 토큰을 폭증시킨다. 내부적으로 단계 계획을 유도하면 중간 산출물도 길어진다.
- 절약 팁: “결론만 간결히”“핵심 요약 5줄” 같이 출력 형식을 제한한다 → max_tokens를 낮춘다 → 중간 단계는 필요할 때만 한 번 요청한다.
ㅇ taskMaster(작업 기획·체크리스트 오케스트레이션)
- 영향: PRD, 작업목록, 체크리스트, 상태 요약이 매번 합쳐지면 입력 토큰이 커진다. 반복 실행 시 동일 맥락을 계속 재전송한다.
- 절약 팁: PRD를 슬림 코어(문제·입력·출력·제약·완료조건 5줄)로 축약하고 상세는 링크로 분리한다 → 작업 단위를 쪼개고 요청도 파일 1개·기능 1개로 쪼갠다 → 반복 호출에는 이전 출력의 해시/버전만 넘기고 전문은 피한다.
ㅁ 내가 겪은 토큰 과소비 사례
- 8월 4일: PRD 기반으로 QA 및 리팩토링을 병행했는데, 전체 폴더 분석과 코드 리팩토링을 반복하다 하루 사용량이 거의 1억 토큰에 도달했다.
- 8월 5~6일: Sentinel 개발, QA 작업 중 main.kt 오류를 해결하려고 대화 컨텍스트를 유지한 채 여러 번 요청 → 불필요하게 컨텍스트를 유지한 탓에 토큰이 빠르게 소모됐다.
- 8월 7일: 비교적 적게 사용한 날(해결 방안이 보이지 않음)도 있었지만, 모델 분석 태스크를 병렬로 돌리면 토큰 사용이 순식간에 늘어남을 확인했다.
ㅁ 토큰 소비 예시
| 작업 유형 | 파일 크기 | 소비 토큰(대략) | 비고 |
| 짧은 코드 수정 요청 | 50줄 | 500~1,000 | 간단한 함수 수정 |
| 프로젝트 전체 분석 | 5,000줄 | 30,000~80,000 |
폴더 구조/의존성 분석
|
| 긴 대화 기반 요청 | - | 2,000~10,000 |
이전 대화 맥락 포함
|
| 자동완성(짧은 코드) | 20줄 | 50~300 |
입력 시마다 반복 소비
|
ㅁ 토큰 절감 체크리스트
내가 실제 경험을 통해 정리한 토큰 절약 팁은 다음과 같다.
- 필요한 범위만 지정해 요청하라
전체 프로젝트를 분석하지 말고, 정말 필요한 파일·코드 블록만 지정한다.
예를 들어, 오류가 발생한 main.kt만 분석해도 충분할 때가 많다. - 대화 컨텍스트를 주기적으로 초기화하라
한 세션이 너무 길어지면 이전 대화 내용이 불필요하게 포함되어 토큰이 급증한다.
필요한 내용만 복사해 새로운 세션에서 시작하는 것이 효율적이다. - 자동완성 범위를 제한하라
.cursorignore파일을 활용해 빌드 폴더, 라이브러리, 불필요한 대형 파일을 제외한다.
특히, Node_modules나 vendor 폴더는 반드시 제외하는 것이 좋다. - 요청 범위를 줄여라
"전체 리팩토링" 대신 "이 함수만 개선", "이 로직만 최적화" 식으로 요청한다.
불필요하게 큰 단위를 보내는 것은 토큰 낭비의 주범이다. - 대규모 변경 전후 비교는 최소화하라
Diff 기반 요청은 변경 전후 코드 전체를 포함하므로, 변경 범위를 작게 나누는 것이 유리하다.
ㅁ 마무리
Cursor는 강력한 AI 개발 도구지만, 토큰은 곧 비용이다.
하루 1억 토큰을 소비하는 폭탄 같은 날이 나오지 않으려면, 요청 범위 조절, 컨텍스트 관리, 자동완성 제어가 필수이다.
토큰 소비 구조를 이해하면, 같은 요금제에서도 더 많은 작업을 할 수 있다.
'AI > AI코딩 | 실습' 카테고리의 다른 글
| [AI] 토큰 사용량을 줄이는 방법, Serena MCP (11) | 2025.08.14 |
|---|---|
| [AI] 토큰 부족, AI 최소 의존 모드 (5) | 2025.08.10 |
| [AI] AI코딩 관련 동영상 모음 (12) | 2025.08.07 |
| [AI] Gemini CLI와 Cursor로 스마트하게 개발하기: 토큰 절약과 효율 극대화 전략 (4) | 2025.07.17 |
| [AI] Cursor v1.2 업데이트 – 더욱 강력해진 기능 소개 (1) | 2025.07.08 |


