
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 공부
- aws
- kotlin
- 코틀린 코루틴의 정석
- AI
- mysql 튜닝
- Kubernetes
- 정보처리기사 실기 기출문제
- kotlin coroutine
- APM
- docker
- 기록으로 실력을 쌓자
- Pinpoint
- 오블완
- Elasticsearch
- minikube
- PETERICA
- kotlin querydsl
- Spring
- tucker의 go 언어 프로그래밍
- CloudWatch
- CKA
- go
- CKA 기출문제
- AWS EKS
- Java
- golang
- 정보처리기사실기 기출문제
- 티스토리챌린지
- Linux
- Today
- Total
피터의 개발이야기
[DevOps] Kube환경 Node, Redis, RDS 성능 업그레이드 작업 정리 본문

ㅁ 개요
ㅇ 성능 시험을 위해 검수기의 서비스 환경을 운영과 동일하게 업그레이드 하는 과정을 정리하였다.
ㅇ 업그레이드는 Node, redis, RDS로 나뉘어서 진행되며, 여기는 Node 업그레이드 과정이다.
ㅁ CloudFormation이란?
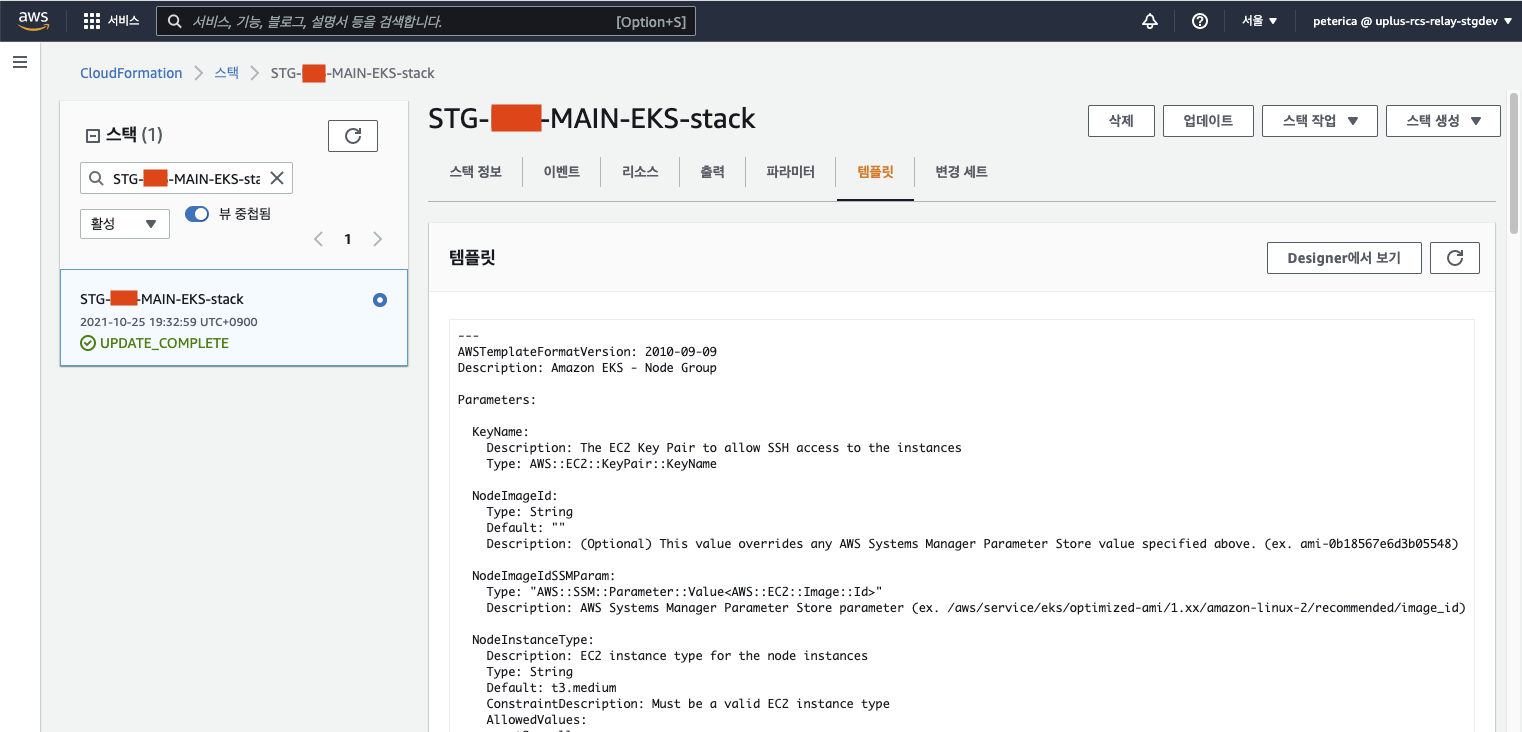
Amazon Web Services(AWS) 리소스를 자동으로 생성해 주는 서비스이다.
사용하려는 AWS 리소스를 템플릿 파일로 작성하면,
CloudFormation이 이를 분석해서 AWS 리소스를 생성한다.
이렇게 생성된 리소스를 스택이라고 한다.
ㅁ 스택 작업
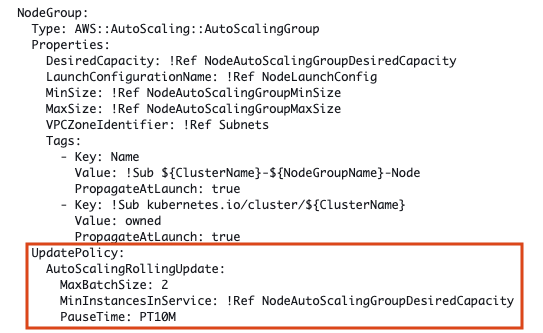
스택 템플릿에 scale up 설정을 하면,
아래의 정책에 따라
UpdatePolicy:
AutoScalingRollingUpdate:
MaxBatchSize: 2
MinInstancesInService: !Ref NodeAutoScalingGroupDesiredCapacity
PauseTime: PT10M
2개의 node가 신규 스팩으로 생성되고, 기존 node는 10분 후 사라지게 된다.
이 때에 node down에 따른 kube에서 즉각적 감지가 안되기 때문에 10분안에 미리 taint 작업을 해야한다.
ㅁ 진행과정
1. CloudFormation > Main 스택
- 업데이트 클릭
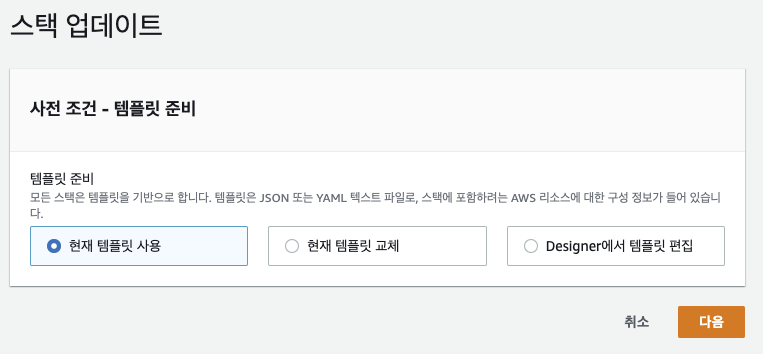
- 현재 템플릿 사용
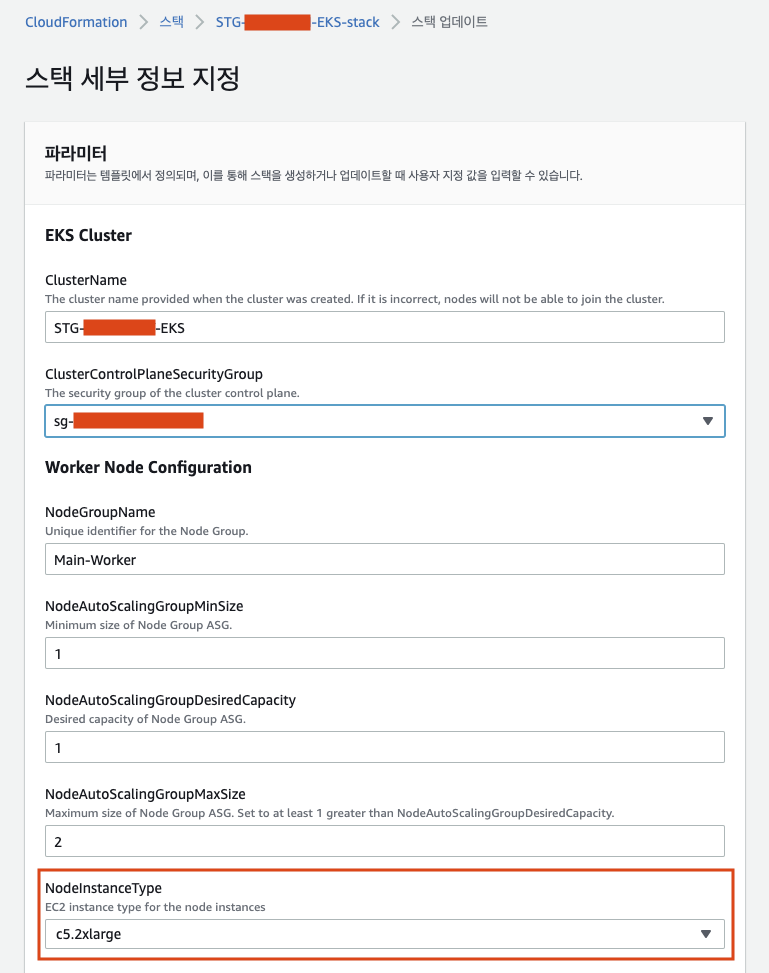
- c5.large -> c5.2xlarge

- 노드의 서비스 라벨을 추가하고 taints도 추가한다.
- '다음' '다음' '스택 업데이트' 버튼 클릭
- 확인 절차
스택이 업데이트가 되면 스택의 해석하여 node가 scale Up이 이루어짐.
1) EC2에서 인스턴스 생성 확인.
2) 스택에서 업데이트 에러 및 진행상황 확인
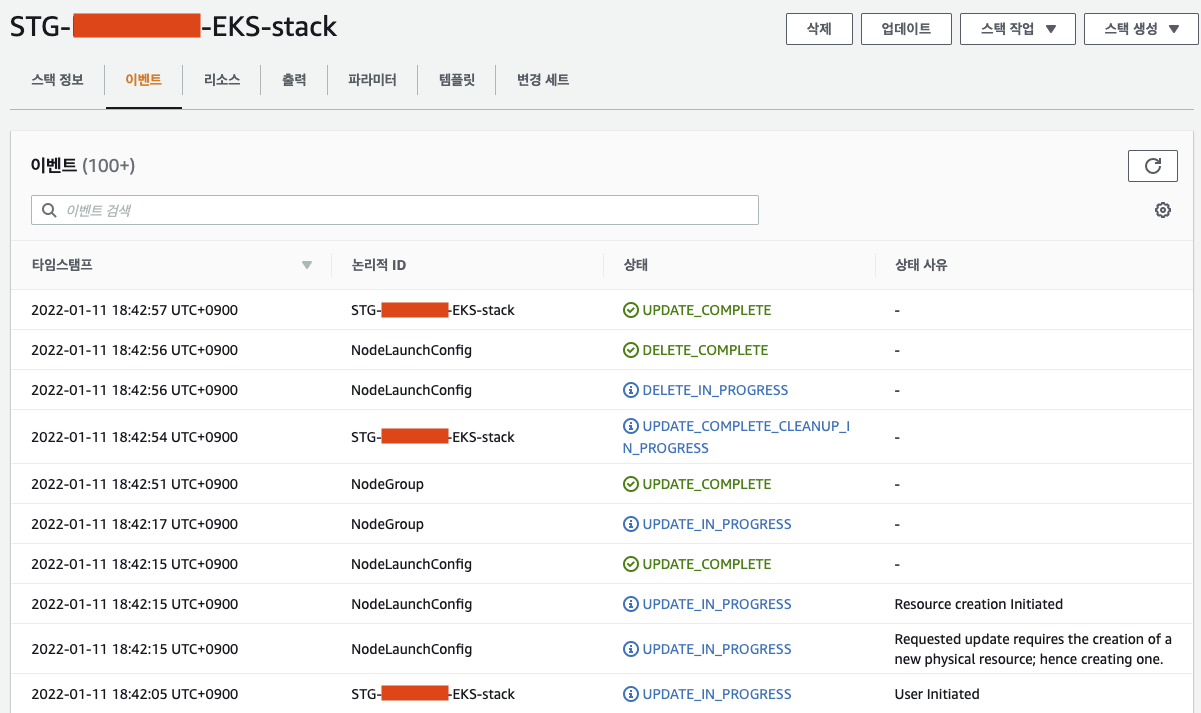
3) wacth kubectl top no -l nodetype=service
4) watch kubectl get hpa
2. main taint 실행
- 기존 노드의 pod들을 강제 종료시키도록 한다.
kubectl taint nodes ip-172-xxx-xxx-xxx.ap-northeast-2.compute.internal key=stop:NoExecute
- pod terminating 확인
kubectl get po -o wide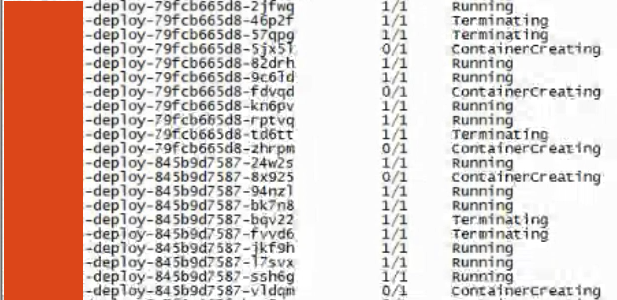
- node 안정화를 확인한다.

ㅇ CUP가 안정이 되었다.
3. autoScaling 조정
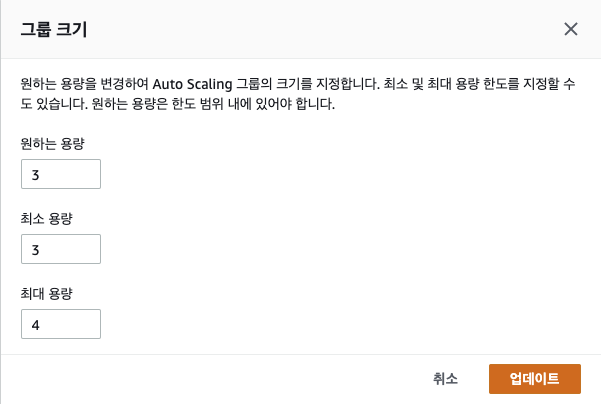
- 편집 max min 각각 3
- instance 생성 확인
4. hpa를 확인한다.
kubectl get deployment
kubectl edit deployment auto-scaling-pod-deploy를 실행하여 Pod Increase 정책을 수정한다.
노드 스팩이 높아져서 노드에 할당할 Pod 갯수를 조종하는 것이다.
5. cloudWatch
- 노드 편집 > 모든지표 > EC2 > 인스턴스별 지 > CPUUtiliztion 검색추가
STG-RCS-RELAY-EKS 검색해서 main, sub 지정.
6. ALB체크
- cloudWatch의 ALB_RS 연결갯수 확인
- ec2 > 대상그룹 > 이름= %gw-r% LB= %stg% > 체크 > 대상 탭 클릭
- unHealthy를 찾아서 pod delete
kubectl delete po {podName}
'DevOps' 카테고리의 다른 글
| [DevOps] AWS RDS Fail Over 처리 후 접속 주의 (0) | 2022.05.26 |
|---|---|
| [Redis] LREM의 큐처리방향에 따른 처리속도지연 정리 (0) | 2022.05.24 |
| [AWS] AutoScale ShutDown 시간 연장하기 (0) | 2022.05.23 |
| [AWS] RDS Aurora 성능 증감 시 작업 과정 정리, fail over 처리 (0) | 2022.05.17 |
| [DevOps 모니터링] 서비스 퍼포먼스를 위한 응답 시간 체크 방법 (0) | 2022.05.14 |



