
- 분류 전체보기 (853)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 오블완
- APM
- kotlin
- AI
- Elasticsearch
- go
- Java
- mysql 튜닝
- CKA 기출문제
- Pinpoint
- Kubernetes
- tucker의 go 언어 프로그래밍
- minikube
- Spring
- aws
- golang
- 정보처리기사실기 기출문제
- Linux
- 코틀린 코루틴의 정석
- 정보처리기사 실기 기출문제
- PETERICA
- AWS EKS
- 기록으로 실력을 쌓자
- CloudWatch
- CKA
- docker
- 티스토리챌린지
- kotlin coroutine
- kotlin querydsl
- 공부
- Today
- Total
피터의 개발이야기
[MySQL 튜닝] MySQL 튜닝 방법 본문

ㅁ 들어가며
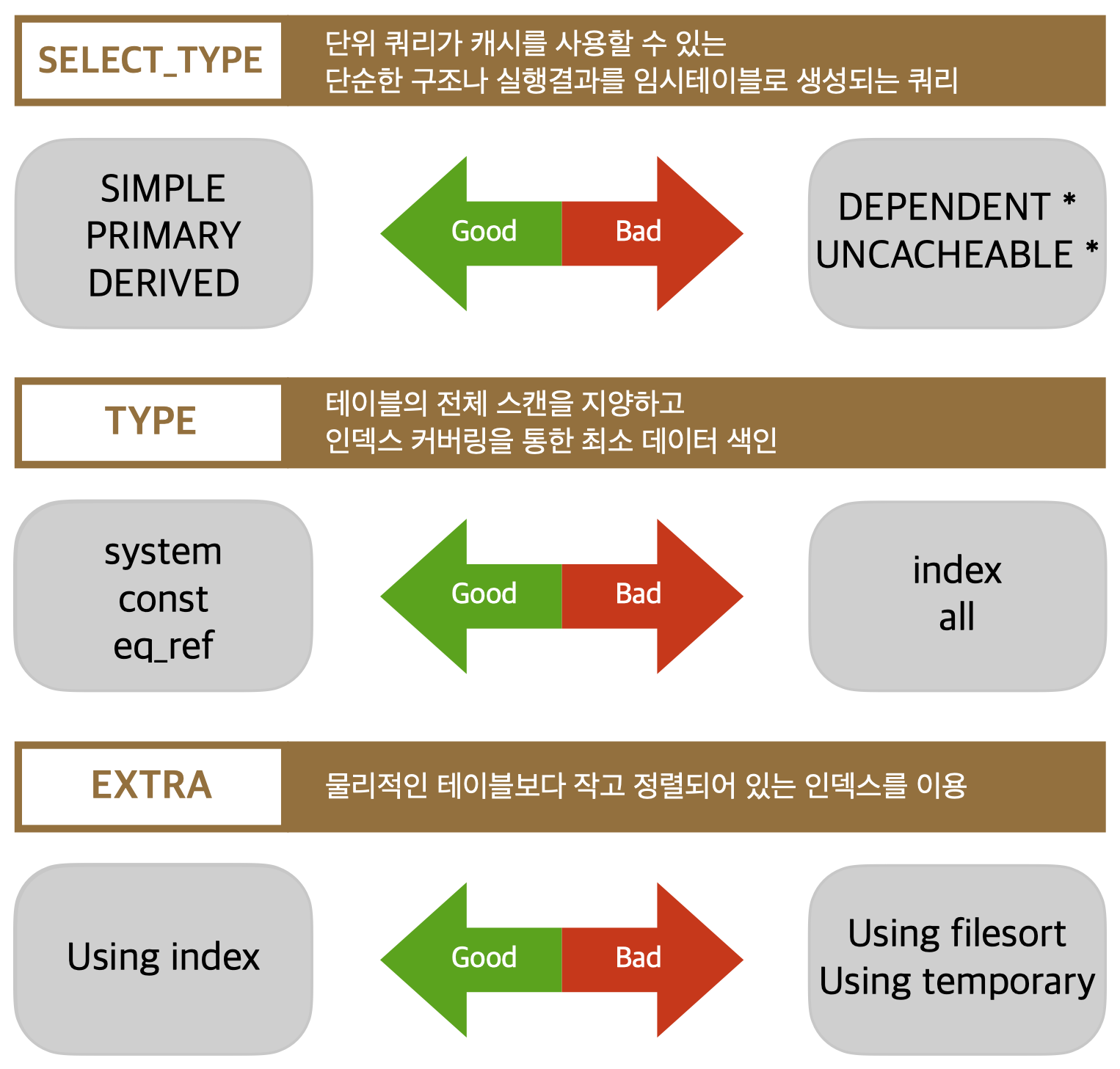
[SQL튜닝] MySQL 쿼리 튜닝, 쿼리 실행계획, Explain에서 쿼리의 튜닝을 위한 Explain을 보는 방법과 Explain 컬럼을 분석하여 최적의 쿼리를 분석하는 방법을 공부하였다. 이번 글에서는 SQL 튜닝 책 4장과 5장을 공부하면서 튜닝의 방법들을 정리해 보았다.
ㅁ Intellij의 확장된 Explain 활용방법
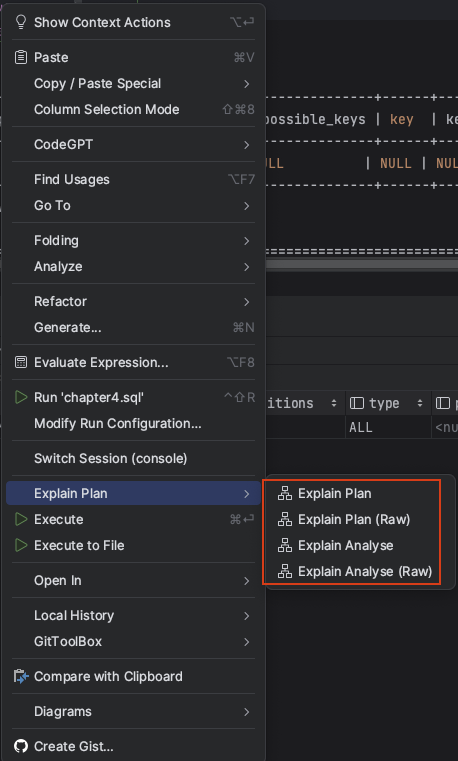
ㅇ Mysql 8.0.18 이상의 경우 Explain Analyze을 제공한다.
ㅇ 위의 캡쳐에서
Explain Plan의 경우 EXPLAIN FORMAT=TREE
Explain Plan(Raw)의 경우 EXPLAIN FORMAT=TRADITIONAL에 해당한다.
와 각각의 Raw 분석을 제공하고 있다. 튜닝을 학습하는 과정에서 개별 Explain를 살펴보고 각각의 분석 내용을 정리해 보았다.
ㅁ 함수사용
SELECT *
FROM 사원
WHERE SUBSTRING(사원번호,1,4) = 1100
AND LENGTH(사원번호) = 5;ㅇ SUBSTRING(emp_no,1,4), LENGTH(emp_no)처럼 함수를 사용하게 되면 기본 키 Index를 사용하지 않고 테이블 풀 스캔을 수행하게 된다. (p175)

ㅇ (Explain) TYPE의 ALL은 전체 테이블을 풀스캔하는 가장 비효율적인 방법이다.

ㅇ (Explain tree) Where의 Filter가 이루어질 때에 사원테이블에 Full Table 스캔이 이루어진다.

ㅇ (Analyze) table: 사원이 Full Table scan임을 알려준다.
ㅇ Actual Rows에서 Full Table scan 300024건과 필터된 10건을 표시하고 개별 단계에서 Actual Total Time을 보여주고 있다.
SELECT *
FROM 사원
WHERE 사원번호 BETWEEN 11000 AND 11009;ㅇ Index 스캔이 가능한 Between 구문으로 변경하였다.

ㅇ (Explain) PRIMARY key를 Range index 스캔을 확인하였다.

ㅇ (tree) index range scan을 하여 10건의 데이터 스캔을 확인 할 수 있다.

ㅇ (Analyze) index range scan이 이루어져서 10건의 데이터를 스캔하였고, 시간도 만분의 1 수준으로 줄어들었다.
ㅁ 묵시적 형변환
SELECT COUNT(1)
FROM 급여
WHERE 사용여부 = 1;ㅇ use_yn은 char(1) 속성을 가지고 있지만, 숫자 유형으로 호출되면서 MySQL은 묵시적형 변환이 이루진다.
ㅇ 결국 use_yn 인덱스를 사용하지 않고 전체 데이터를 스캔한다.(p183)

ㅇ (Explane)의외적으로 Idnex 튜닝이 수행되었다.

ㅇ(tree)

ㅇ (Analyze)
ㅁ 불필요 정렬 제거
SELECT 'M' AS gender, e.emp_no
FROM employees e
WHERE e.gender = 'M'
AND e.first_name ='Baba'
UNION
SELECT 'F', e.emp_no
FROM employees e
WHERE e.gender = 'F'
AND e.first_name = 'Baba';ㅇ UNION 연산자는 두개의 SELECT 문의 데이터를 합치는 과정에서 임시 테이블을 만들어 정렬 후 중복을 제거한다.
ㅇ 단순하게 결과데이터를 합치는 경우 UNION ALL 연산자를 사용하여 불필요한 정렬 및 중복제거 로직을 피할 수 있다. (p196)
ㅁ Index 컬럼 순서와 Group By 컬럼 순서
SELECT 성, 성별, COUNT(1) as 카운트
FROM 사원
GROUP BY 성별, 성;
ㅇ 인덱스의 순서는 성, 성별이다. 하지만 Group By의 순서가 다른 경우 using temprory table에 추가적인 작업을 수행함을 알 수 있다.

ㅇ Group by의 컬럼 순서를 변경하여 조회 시 Full Index Scan을 하여 추가적인 임시테이블 생성 Cost를 줄일 수 있다.(p200)
ㅁ USE INDEX
SELECT 사원번호
FROM 사원
WHERE 입사일자 LIKE '1989%'
AND 사원번호 > 100000;ㅇ 옵티마이져가 최적화를 정하지만, 때로는 잘못된 인덱스를 참조하는 경우가 있다.
ㅇ 위 쿼리에서 사원번호 PRIMARY 인덱스를 사용하지만 idx_hire_date 인덱스가 더 많은 데이터를 필터할 수 있어 유리하다.
ㅇ 이럴 경우 강제적으로 USE INDEX 명령어를 통해 INDEX를 지정할 수 있다.(p207)

ㅇ (tree) 사원 테이블의 PRIMARY 인덱스를 스캔한 후(149689건)
ㅇ 입사일자 LIKE '1989%' AND 사원번호 > 100000 조건에 의해 필터되어 16630건 추출된다.

ㅇ (Analyze) tree에서 분석된 내용 플러스 actual total time 지표를 확인할 수 있다.
SELECT 사원번호
FROM 사원 USE INDEX(I_입사일자)
WHERE 입사일자 LIKE '1989%'
AND 사원번호 > 100000;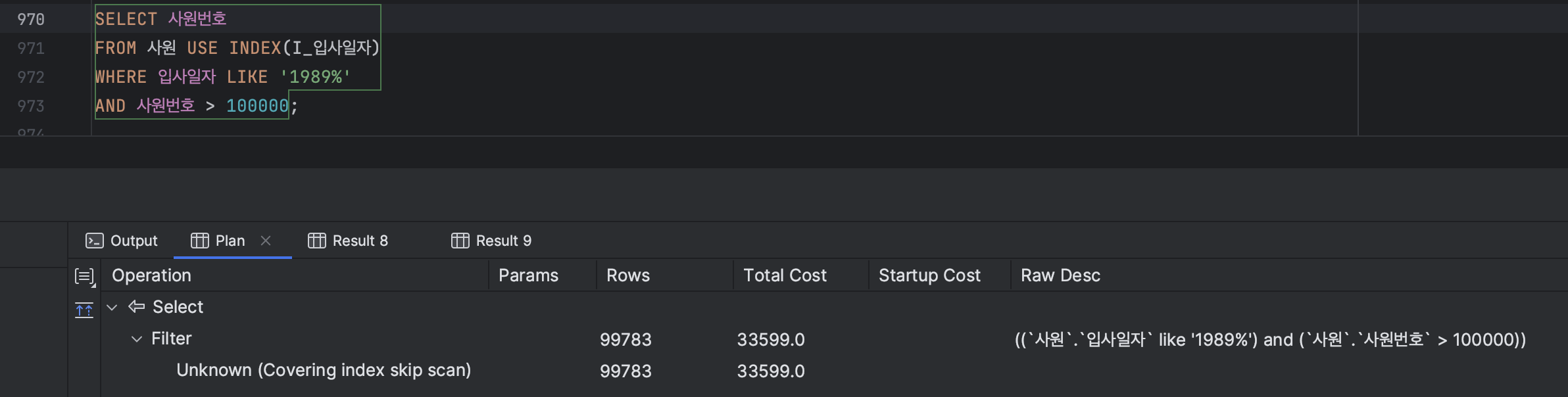
ㅇ Use Index 힌트를 사용하여 기존 Primary 조회가 아닌 Covering index 스캔이 가능한 입사일자 인덱스를 변경하였다.
ㅁ IGNORE INDEX
SELECT *
FROM 사원출입기록 IGNORE INDEX(I_출입문)
WHERE 출입문 = 'B';ㅇ USE INDEX와 반대의 경우 무시하려는 인덱스를 IGNORE INDEX로 추가할 수 있다.
ㅇ 인덱스의 장점은 적은 데이터로 색인과정으로 빠르게 필요한 데이터를 추출하는데 있다.
ㅇ 하지만 필요한 데이터가 전체의 50%가 넘는 경우 오버헤드가 발생할 수 있다.
인덱스를 조회하고 데이터를 조회하기 때문에 이중의 색인으로 오히려 오버헤드가 발생한다.
이럴 경우 인덱스를 배제하는 것이 더 효율적이다.(p210)
ㅁ STRAIGHT_JOIN
ㅇ STRAIGHT_JOIN은 왼쪽 테이블이 항상 오른쪽 테이블보다 먼저 읽힌다는 점을 제외하면 JOIN과 유사하다.
SELECT 매핑.사원번호, 부서.부서번호
FROM 부서사원_매핑 매핑, 부서
WHERE 매핑.부서번호 = 부서.부서번호
AND 매핑.시작일자 >= '2002-03-01';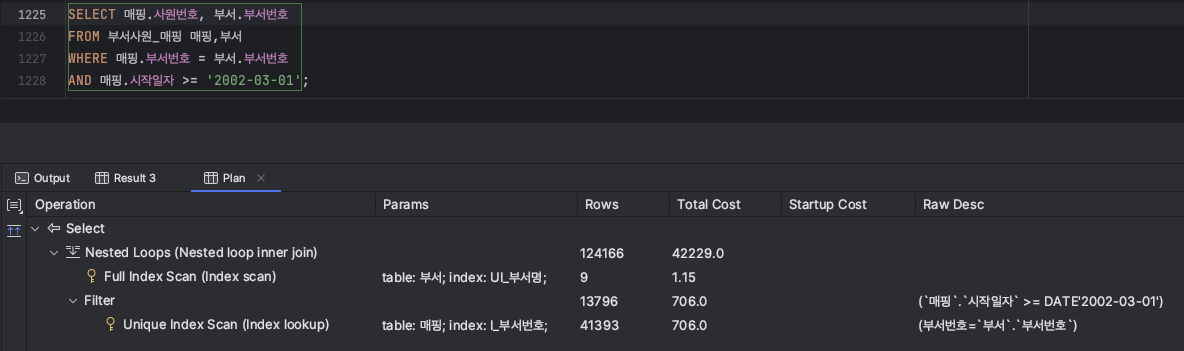
ㅇ Nested Loops 조인의 경우 드라이브 테이블의 필터를 우선할 경우 튜닝의 효과가 있다.
ㅇ 부서(드라이브 테이블)와 매핑 테이블(드리븐 테이블)이 먼저 조인이 이루어져 331603건에서 시작일자로 필터되고 있다.
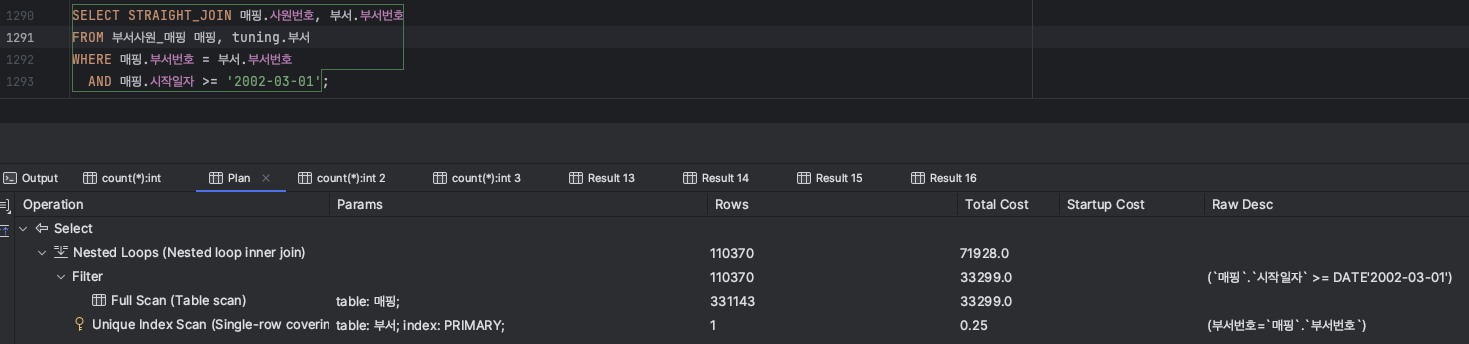
ㅇ 만약 드라이브 테이블이 시작일자로 필터(1341건) 가 되고, 부서 테이블로 드리븐 된다면 속도 개선이 이루어진다.
ㅇ STRAIGHT_JOIN를 이용하여 매핑테이블이 드라이브 되도록 유도하였다.(p220)
ㅁ 함께 보면 좋은 사이트

'Database > SQL 튜닝' 카테고리의 다른 글
| [MySQL] 인덱스(Index) 정리 및 효율화 방법 (1) | 2024.02.26 |
|---|---|
| [MySQL] 파티션 테이블별 용량 조회 (0) | 2023.10.16 |
| [SQL튜닝] MySQL 쿼리 튜닝, 쿼리 실행계획, Explain (0) | 2023.08.31 |
| [MySQL 튜닝] IN vs INNER JOIN vs EXISTS 성능비교 (0) | 2023.08.18 |
| [MySQL 튜닝] EXISTS를 이용한 SQL 튜닝 (0) | 2023.08.17 |



