
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- Spring
- LLM
- minikube
- PETERICA
- kotlin coroutine
- CKA
- 공부
- SRE
- CloudWatch
- kotlin
- MySQL
- 티스토리챌린지
- 코틀린 코루틴의 정석
- 바이브코딩
- HARNESS
- AWS EKS
- tucker의 go 언어 프로그래밍
- 기록으로 실력을 쌓자
- Kubernetes
- Claude
- Rag
- AI
- docker
- aws
- Java
- 오블완
- 정보처리기사 실기 기출문제
- CKA 기출문제
- go
- golang
- Today
- Total
피터의 개발이야기
[SQL튜닝] MySQL 쿼리 튜닝, 쿼리 실행계획, Explain 본문

ㅁ 들어가며

백엔드개발을 하면서 DB SQL의 튜닝작업은 필수입니다. 쿼리 튜닝 공부를 위해 SQL 튜닝, Real MySQL를 보고 있는데요. 쿼리를 최적화 하기 위해서는 Explain를 잘 분석할 줄 알아야 합니다. 이번 글에서는 Explain의 컬럼과 그 요소들의 의미를 정리하였습니다.
ㅁ Explain 보는 방법

Explain 명령어를 SQL 앞에 붙여 실행하면 쿼리의 실행계획을 볼 수 있습니다.
옵티마이저는 이 SQL을 해석하여 최적의 실행계획을 세웁니다. 하지만 항상 최적의 실행계획을 만들어 낼 수는 없습니다.
그래서 이를 보완하기 위해 Explain 명령어로 옵티마이저가 산출한 실행 계획(Explain)을 사용자가 확인할 수 있습니다.
ㅇ 참조: SQL튜닝 123p, Real MySQL 416p
Explain의 컬럼이 무엇이 있고 어떤 의미있지 알아봅시다.
ㅁ Explain 컬럼
| 실행 계획 | 설명 |
| id | SQL이 수행되는 쿼리 별 부여되는 식별값 |
| select_type | 각 단위 SELECT 쿼리가 어떤 타입의 쿼리인지 표시되는 칼럼 |
| table | 접근하고 있는 테이블에 대한 표시 |
| partitions | 테이블에 파티셔닝이 되어 있는 경우 사용되는 필드 |
| type | 각 테이블의 레코드를 어떻게 읽었는지에 대한 접근 방식 |
| possible_keys | “사용될 법했던 인덱스의 목록”이며 반드시 사용된 것은 아님 |
| key | 최종 선택된 실행 계획에서 사용되는 인덱스 |
| key_len | 선택된 인덱스의 길이를 의미 |
| ref | 접근 방법이 ref면 참조 조건(equal 비교 조건)으로 어떤 값이 제공됐는지 표시 |
| rows | 실행 계획의 효율성 판단을 위해 예측했던 레코드 건수를 보여준다. (정확하지는 않음) |
| filtered | 필터링되고 남은 레코드의 비율 (정확하지는 않음) |
| Extra | 쿼리 실행 계획에서 성능에 관련된 중요한 내용이 Extra 칼럼에 자주 표시됨 내부적인 처리 알고리즘에 대해 조금 더 깊이있는 내용을 보여주는 경우가 많음 옵티마이저가 어떻게 동작하는지에 대해 알려주는 힌트 값 |
실행 계획을 통해 튜닝 대상을 찾을 때에는 select_type, type, extra 컬럼을 중점적으로 살펴야 합니다.
핵심은 이 컬럼의 요소에 따라 좋은 쿼리와 나쁜 쿼리를 판단할 줄 알아야 합니다.
구체적으로 각각의 구분과 설명을 이해하고 튜닝이 필요한 구분값을 확인할 줄 알아야 합니다.
ㅁ Select_type
| 구분 | 설명 |
| SIMPLE | Union이나 Sub Query가 없는 단순 Select |
| PRIMARY | Sub Query에서 가장 바깥쪽(Outer) Select |
| DERIVED | 단위 SELECT 쿼리의 실행 결과로 생성된 임시테이블 |
| SUBQUERY | select와 from 절 사이에서 독립적 수행 쿼리 select (select from) from |
| UNION | Union 쿼리의 Select 중 두번째, 첫번째는 결과를 담는 임시 테이블(DERIVED) |
| UNION RESULT | UNION RESULT는 UNION 결과를 담아두는 테이블 |
| MATERIALIZED | 서브쿼리의 내용을 임시테이블로 구체화(Materialization)한 상태 |
| DEPENDENT SUBQUERY | SUBQUERY에서 외부와 where 조건이 연결되어 있는 쿼리 |
| DEPENDENT DERIVED | MySQL8.0 이후 LATERAL JOIN이 지원되면서 서브쿼리에서 외부컬럼을 참조 가능. |
| DEPENDENT UNION | UNION 또는 UNION ALL 쿼리에서 두번째 단위 쿼리 |
| UNCACHEABLE UNION | 캐시를 사용하지 못하는 UNION |
| UNCACHEABLE SUBQUERY | 캐시를 사용하지 못하는 SUBQUERY(사용자 변수 사용 시, UUID RAND 등 결과값이 달라지는 경우) |

ㅇ SELECT문이 단순히 FROM절에 위치한 것인지, 서브쿼리인지, UNION절로 묶인 SELECT문인지를 알 수 있습니다.
ㅇ type은 조회 시 외부테이블을 참조하기 때문에 성능에 악역향을 미칠 수 있습니다.
ㅇ UNCACHEABLE *, DEPENDENT * 값에 해당 될 경우 성능적으로 불리하기 때문에 SQL튜닝 대상이 됩니다.
ㅇ 되도록이면 RAND(), UUID() 함수는 사용하지 않도록 해야 합니다.
ㅇ MySQL 공식 설명(explain-output-columns)
ㅁ TYPE
| 실행 계획 | 설명 |
| system | 테이블에 단 한개의 데이터만 있는 경우 |
| const | SELECT에서 Primary Key 혹은 Unique Key를 기준으로 조회하는 경우로 많아야 한 건의 데이터만 있음 |
| eq_ref | 조인을 할 때 Primary Key로 검색되는 경우 |
| ref | 조인을 할 때 Primary Key 혹은 Unique Key가 아닌 Key로 매칭하는 경우 |
| ref_or_null | ref 와 같지만 null 이 추가되어 검색되는 경우 |
| index_merge | 두 개의 인덱스가 병합되어 검색이 이루어지는 경우 |
| unique_subquery | 다음과 같이 IN 절 안의 서브쿼리에서 Primary Key가 오는 특수한 경우 SELECT * FROM tab01 WHERE col01 IN (SELECT Primary Key FROM tab01); |
| index_subquery | unique_subquery와 비슷하나 Primary Key가 아닌 인덱스인 경우 SELECT * FROM tab01 WHERE col01 IN (SELECT key01 FROM tab02); |
| range | 특정 범위 내에서 인덱스를 사용하여 원하는 데이터를 추출하는 경우로, 데이터가 방대하지 않다면 단순 SELECT 에서는 나쁘지 않음 |
| index | 인덱스를 처음부터 끝까지 찾아서 검색하는 경우로, 일반적으로 인덱스 풀스캔이라고 함 |
| all | 테이블을 처음부터 끝까지 검색하는 경우로, 일반적으로 테이블 풀스캔이라고 함 앞선 방식으로 처리할 수 없을 때 가장 마지막에 선택하는 가장 비효율적인 방법 |

ㅇ Type은 테이블의 데이터를 어떻게 찾을지에 관한 정보를 제공합니다.
ㅇ 좋은 쿼리의 조건은 테이블 전체 스캔을 지양해야하고 인덱스를 통한 커버링 인덱스를 지향하도록 튜닝이 필요합니다.
ㅇ Type에서의 주 튜닝 포인트는 검색하는 데이터의 수를 줄이는 방법에 있다.
ㅇ 위의 타입을 좋은 쿼리에서 좋지 않은 쿼리로 나열해 보면
제일 좋은 상황인 테이블에 한건 -> 테이블 인덱스 조회로 한건 조회 -> 조인된 N건에 Primary Key로 한건씩 조회
-> 전체 인덱스 조회 -> 전체 테이블 테이터 조회의 순으로 조회의 건수와 색인하려는 데이터용량이 증가하고 있다.
ㅇ MySQL 공식 설명(EXPLAIN Join Types)
ㅁ EXTRA
| 구분 | 설명 |
| using index | 물리적 데이터를 읽지 않고 인덱스를 이용해서 데이터를 추출 하는 경우 인덱스만으로 처리되는 방법을 "커버링 인덱스(Covering Index)"라고 함 |
| using where | where 조건으로 데이터를 추출. type이 ALL 혹은 Indx 타입과 함께 표현되면 성능이 좋지 않다는 의미 |
| distinct | 조건을 만족하는 레코드를 찾았을 때 같은 조건을 만족하는 또 다른 레코드가 있는지 검사하지 않음 |
| not exist | left join 조건을 만족하는 하나의 레코드를 찾았을 때 다른 레코드의 조합은 더 이상 검사하지 않는다 |
| range checked for each record | 최적의 인덱스가 없는 차선의 인덱스를 사용한다는 의미 |
| using filesort | 이미 정렬된 인덱스를 사용하지 못할 경우, 추가적인 데이터 정렬을 위해 메모리 혹은 디스크에서 정렬하는 상황임. 속도개선을 위해서는 인덱스 추가 대상이됨. |
| using temporary | 데이터의 중간 결과를 임시 테이블로 생성 보통 DISTINCT, GROUP BY, ORDER BY 구문이 포함된 경우임. |
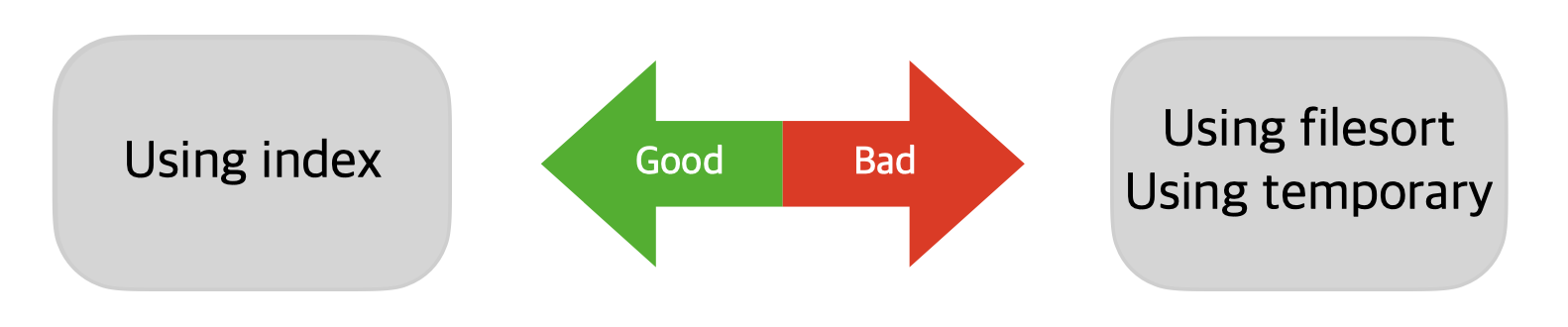
ㅇ EXTRA는 SQL문을 어떻게 수행할 지 가장 구체적인 정보를 제공해 줍니다.
ㅇ 가장 좋은 방법은 물리적인 테이블보다 작고 정렬되어 있는 인덱스를 이용할 때에 가장 효율적입니다.
ㅇ 인덱스를 사용하지 못하는 using filesort, using temporary의 경우 튜닝의 대상이 됩니다.
ㅇ 참조: SQL튜닝 146p, Real MySQL 456p
ㅇ MySQL 공식 설명(EXPLAIN Extra Information)
ㅁ 함께 보면 좋은 정보


ㅇ MySQL 공식문서(EXPLAIN Output Format)
ㅇ https://zzang9ha.tistory.com/436
MySQL EXPLAIN 실행계획 마스터하기(feat. RealMySQL 8.0)
💯 MySQL EXPLAIN 실행계획 마스터하기(feat. RealMySQL 8.0) 실행 계획(EXPLAIN) 이란? 대부분의 DBMS는 많은 데이터를 안전하고, 빠르게 저장 및 관리하는 것이 주목적이다. 이러한 목적을 달성하기 위해 사
zzang9ha.tistory.com

'Database > SQL 튜닝' 카테고리의 다른 글
| [MySQL] 인덱스(Index) 정리 및 효율화 방법 (1) | 2024.02.26 |
|---|---|
| [MySQL] 파티션 테이블별 용량 조회 (0) | 2023.10.16 |
| [MySQL 튜닝] MySQL 튜닝 방법 (0) | 2023.09.06 |
| [MySQL 튜닝] IN vs INNER JOIN vs EXISTS 성능비교 (0) | 2023.08.18 |
| [MySQL 튜닝] EXISTS를 이용한 SQL 튜닝 (0) | 2023.08.17 |



