
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- AI
- tucker의 go 언어 프로그래밍
- SRE
- 정보처리기사 실기 기출문제
- kotlin coroutine
- Java
- PETERICA
- 바이브코딩
- MySQL
- Rag
- Linux
- Pinpoint
- minikube
- 티스토리챌린지
- kotlin
- Kubernetes
- CloudWatch
- 공부
- AWS EKS
- CKA
- CKA 기출문제
- 오블완
- LLM
- golang
- 기록으로 실력을 쌓자
- 코틀린 코루틴의 정석
- Spring
- aws
- go
- APM
- Today
- Total
피터의 개발이야기
[linux] awk 사용법 본문

이 글은 김태용,『 김태용의 쉘 스크립트 프로그래밍 입문』,제이펍(2009), 402~418p
을 보고 정리한 내용입니다. 공부하면서 더 자세한 블러그는 아래에 링크 참조하였습니다.
awk란
데이터를 조작하고 리포트를 생성하기 위해 사용하는 언어입니다.
Alfred Aho, Peter Weinberger, Brian Kernighan 3명이 만들었는데 이들의 이름 이니셜을 가져와서 awk라고 부릅니다.
awk는 파일에서 레코드를 선택하고, 선택된 레코드에 포함된 레코드 값을 핸들링하거나 데이터화 합니다.
선택의 방법으로 패턴 탐색과 처리를 위한 명령어로 간단하게 파일에서 결과를 추려냅니다.
데이터화 방법으로 선택된 값을 가공하여 원하는 결과물을 만들어 냅니다.
awk가 할 수 있는 일
- 파일의 특정필드만 출력
- 특정 필드에 문자열을 추가해서 출력
- 패턴이 포함된 레코드 검색 출력
- 필드 값에 연산 조건에 따라 레코드 출력
awk 동작 원리
1) 먼저 awk는 파일 또는 파이프를 통해 입력 라인을 얻어와 $0라는 내부 변수에 라인을 입력해 둡니다. 각 라인은 레코드라고 부르고, newline에 의해 구분됩니다.
2) 라인은 공백을 기준으로 각각의 필드나 단어로 나눕니다. 필드는 $1부터 시작하여 많게는 100개 이상의 필드를 저장할 수 있습니다.
3) awk가 어떻게 공백을 사용하여 필드를 나눌까?
내장 변수인 FS라고 부르는 필드 분리자가 공백을 할당받습니다. 필드가 콜론이나 대시와 같은 문자에 의해 분리되면 새로운 필드 분리자로 FS의 값을 변경할 수 있습니다.
4) awk는 화면에 필드를 출력할 때 print 함수를 사용합니다.
5) awk가 화면에 출력을 하고 나면 파일의 다음 라인이 호출되고 $0으로 저장됩니다. 기존 변수를 덮어쓰기어 쓰면서 모든 라인이 반복적으로 처리됩니다.
기본 문법
$ awk 'pattern' filename
$ awk '{action}' filename
$ awk 'pattern {action}' filename
샘플
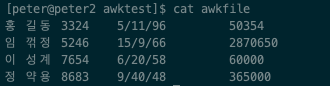
전체파일 출력, {action}
> awk '{print $0}' awkfile
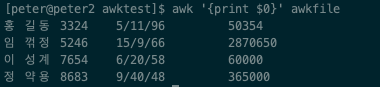
특정필드 출력, {action}
> awk '{print $1}' awkfile
공백으로 분리하여 인자값을 제공한다.
$1: 홍 $2: 길동 $3: 3324 $4: 5/11/96 $5: 50354
pattern을 이용한 레코드 검색
> awk '/길동/' awkfile

패턴이 포함된 레코드 검색 후 특정 필드에 문자열을 추가해서 출력
> awk '/정/{print "\t안녕하세요? " $1, $2 "님!"}' awkfile

printf 포맷 지정자
탭키를 사용하는 print 함수는 깔끔한 출력을 보장하지 못한다.
printf는 출력문자 형태를 지정할 수 있어 깔끔한 출력을 할 수 있다고,
newline (\n)도 제공한다.
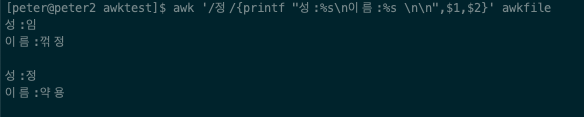
> awk '/정/{printf "성:%s\n이름:%s \n\n",$1,$2}' awkfile
awk -f 옵션
awk 액션과 명령이 파일에 작성되어 있다면 -f 옵션을 사용합니다.
awk -f [awk 명령파일] [awk 명령을 적용할 텍스트 파일]> vi awkcommand
{print "안녕하세요 " $1, $2"님"}
{print $1, $2, $3, $4, $5}
패턴에 조건을 포함하여 검색
> awk '$3 >6000' awkfile

> '-'가 붙으면 좌측에서 시작되고 기본형이면 우측에서 시작된다.

특정 필드들의 합 구하기
> awk '{ for (i=1; i<=NF; i++) total += $i }; END { print "TOTAL : "total }' awkfile2

NF 는 레코드의 필드 개수를 나타내는 builtin 변수입니다.
Record 분리 방법
레코드 분리에 관계된 builtin 변수는 RS( Record Seperator ) 와 RT( Record Terminator ) 입니다.
RS 변수에 설정되는 값은 문자가 두 개 이상이면 regexp 로 해석됩니다.
그러므로 단순히 RS='XXX' 로 설정하면 "XXX" 를 만나면 레코드가 분리되지만 RS='X+' 로 설정하게 되면 이것은 "X", "XX", "XXX" ... 모두에서 분리가 됩니다.
이때 'X+' regexp 과 매칭된 값이 RT 변수에 설정되게 됩니다.
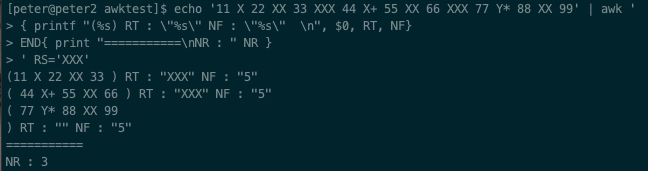
다음은 RS 값에 따라 레코드가 분리되어 $0 변수에 대입되고 RT 값이 설정되는 것을 알아보기 위한 테스트입니다.
printf 문에 (%s) 를 사용하였으므로 괄호 안의 값이 공백을 포함하여 실제 분리된 레코드 값이 됩니다.
첫 번째 예는 RS='XXX' 로 설정한 경우입니다. 입력되는 데이터에 'XXX' 가 두 개 있으므로 레코드가 세 개로 분리되고 이때 RT 값은 동일하게 'XXX' 설정되는 것을 볼 수 있습니다.
자세한 aws script 설명은 여기를 확인하세요.
NR 변수 : 각 레코드들의 번호는 awk의 빌트인 변수 NR에 저장된다. 레코드가 저장된 다음 NR의 값은 하나씩 증가한다
> awk '{print NR, $0}' awkfile

필드 분리 방법
awk의 빌트인 변수 FS는 입력 필드 분리자의 값을 가지고 있습니다. FS의 디폴트값으로 공백과 탬이입니다. FS 값은 -F를 사용하여 변경함.
> awk -F: '/홍/{print $1, $2}' awkfile_F

awk와 정규표현식
문법은 슬러시(/)로 쌓여있다.
> awk '/^정/{print $1, $2, $3}' awkfile

첫글자가 정 레코드 검색.
> awk '/^[0-9]+ /' awkfile2

첫글자가 숫자인 레코드 검색.
awk에서 지원하는 메타문자
| awk 메타문자 | 의미 |
| ^ | 문자열의 시작과 매칭 |
| $ | 문자열의 끝과 매칭 |
| . | 문자 한 개와 매칭 |
| * | 문자가 없거나 그 이상가 매칭 |
| + | 하나의 문자 또는 그이상과 매칭 |
| - | 문자가 없거나 하나와 매칭 |
| [ABC] | A,B,C 문자 중 하나 매칭 |
| [^ABC] | A,B,C 문자 중 하나도 매칭되지 않을 경우 |
| [A-Z] | A에서 Z까지의 범위에서 매칭되는 문자가 있음 |
| A|B | A 또는 B 문자 매칭 |
| (AB)+ | AB 문자셋이 하나 이상 매칭 (예) AB,ABAB,ABABAB |
| \* | 아스테리스크(*) 문자와 매칭 |
| & | 검색 문자열에서 검색된 문자열로 대체할 때 사용 |
match 연산자
> awk '$2 !~ /동$/' awkfile

2번째 필드가 동으로 안끝나는 경우
비교 표현식
> awk '$3 > 7000{print $1, $2}' awkfile

조건식 사용
> awk '{max=($3 > $5) ? $3 : $5; print max}' awkfile

조건식 사용 ($3 > $5) ? $3 : $5
산술 연산자 사용
> awk '$5 - $3 > 200000' awkfile

논리 연산자 사용
> awk '$3 < $5 && $5 >= 100000' awkfile
- && : AND 연산
- || : OR 연산
- ! : NOT 연산
awk 변수
ARGC : ARGV 배열 요소의 갯수.
ARGV : command line argument에 대한 배열.
CONVFMT : 문자열을 숫자로 변경할 때 사용할 형식. (ex, "%.6g")
ENVIRON : 환경변수에 대한 배열.
FILENAME : 경로를 포함한 입력 파일 이름.
FNR : 현재 파일에서 현재 레코드의 순서 값.
FS : 필드 구분 문자. (기본 값 = space)
NF : 현재 레코드에 있는 필드의 갯수.
NR : 입력 시작 점에서 현재 레코드의 순서 값.
OFMT : 문자열을 출력할 때 사용할 형식.
OFS : 결과 출력 시 필드 구분 문자. (기본 값 = space)
ORS : 결과 출력 시 레코드 구분 문자. (기본 값 = newline)
RLENGTH : match 함수에 의해 매칭된 문자열의 길이.
RS : 레코드 구분 문자. (기본 값 = newline)
RSTART : match 함수에 의해 매칭된 문자열의 시작 위치.BEGIN 패턴
- awk가 입력 파일의 라인들을 처리하기 이전에 실행되며 액션 블록 앞에 놓임
- 입력 파일 없이 테스트할 수 있고, 빌트인 내장 변수(OFS, RS, FS)들의 값을 변경할 경우 사용
> awk 'BEGIN{FS=":"; OFS="\t"; ORS="\n\n";}{print $1,$2,$3}' awkfile_FS

END 패턴
- 어떤 입력 라인과도 매칭되지 않고, 입력 모든 라인이 처리된 후 실행됨
- BEGIN만 사용할 경우엔 아규먼트 파일명을 적지 않아도 되지만 END 블록을 사용할 경우엔 반드시 아규먼트 파일을 적어야 함
> awk '/Tom/{count++}END{print "Tom was found " count " times."}' awkfile5

awk 리다이렉션
출력 리다이렉션
- awk결과를 리눅스 파일로 리다이렉션할 경우 쉘 리다이렉션 연산자를 사용합니다.
- 파일명은 큰따옴표로 지정합니다.
> awk -F: '$4 >= 60000 {print $1, $2 > "new_file"}' awkfile5

입력 리다이렉션
getline 함수
표준 입력, 파이프, 현재 처리되고 있는 파일로부터 입력을 읽기 위해 사용. 입력의 다음 라인을 가져와 NF, NR, FNR 빌트인 변수를 설정
레코드가 검색되면 1을 리턴하고, 파일의 끝이면 0을 리턴. 에러가 발생하면 -1을 리턴
> awk 'BEGIN{ "date " | getline d; split(d, contry) ; print contry[6]}' == KST

> awk 'BEGIN{while ((getline < "/etc/passwd") > 0)lc++; print lc}'

/etc/passwd 파일에서 라인을 읽어들입니다.
이때에 getline 함수에 의해
파일이 존재하지 않으면 -1
파일의 끝에 도달하면 0을 리턴한다.
조건식 (getline < "/etc/passwd") > 0 은
파일이 있고 그 파일의 끝까지 도달하기 전까지
계속 레코드를 읽어라는 뜻이다.
결국 파일을 끝까지 읽을 때까지의 라인 개수를 파악하게 된다.
awk 파이프
awk 프로그램에서 파이프를 오픈하고 또다른 파이프를 오픈하기 전에 기존 파이프는 닫아주어야 합니다.
파이프 심볼의 오른쪽 명령은 큰따옴표(““)로 둘러싸야 합니다.
> awk '{print $1, $2 | "sort -r"}' cars

END블록에 close를 사용해 파이프를 꼭 닫아줘야 합니다.
> awk '{print $1, $2 | "sort -r"} END{close("sort -r")}' cars

awk 명령어 사용예제는 여기를 참조하세요.
참고 도서 및 사이트
김태용,『 김태용의 쉘 스크립트 프로그래밍 입문』,제이펍(2009), 402~418p
awk-script 심도있는 이해를 위해 참고
'Linux' 카테고리의 다른 글
| [Linux] 리눅스 시간을 한국(KST)로 바꾸기 (0) | 2022.08.24 |
|---|---|
| [linux] CentOS 버전 확인하기 (0) | 2021.02.05 |
| [linux] grep 사용법 (0) | 2020.12.28 |
| [Linux] 시스템 로그에서 특정값 이상의 로그 추출 (0) | 2020.12.03 |
| [Linux] 시스템 / 프로세스 메모리 사용량 확인 (0) | 2020.12.02 |



