
- 분류 전체보기 (871)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Java
- 정보처리기사 실기 기출문제
- 정보처리기사실기 기출문제
- 코틀린 코루틴의 정석
- minikube
- CKA
- SRE
- PETERICA
- Pinpoint
- AWS EKS
- CloudWatch
- AI
- Elasticsearch
- go
- APM
- Linux
- golang
- kotlin coroutine
- aws
- MySQL
- Spring
- 티스토리챌린지
- tucker의 go 언어 프로그래밍
- kotlin
- Kubernetes
- 공부
- kotlin querydsl
- 오블완
- CKA 기출문제
- 기록으로 실력을 쌓자
- Today
- Total
피터의 개발이야기
[Spring] parallelStream, Intercom 데이터 백업하기 본문

서론
회사에서 Intercom을 사용하고 있습니다. 고객과의 상담 내용을 백업하고자 Intercom API를 연동하는 작업을 정리하였습니다.
백업의 필요성
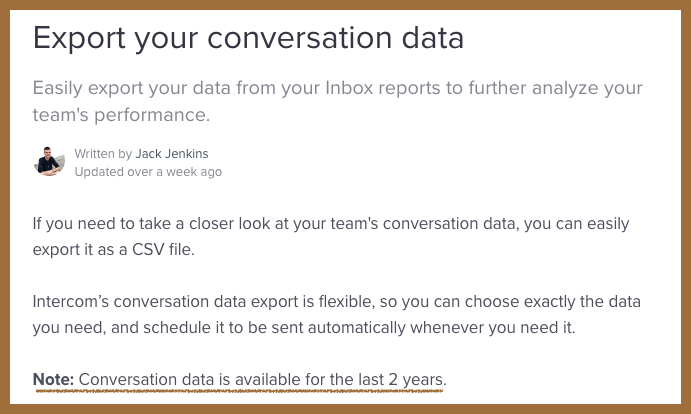
Note를 보면 Conversation(대화방)은 2년동안의 데이터만 확인 할 수 있어 과거 상담내역은 따로 백업을 해야합니다.
그리고 저장된 상담내용은
1. 고객과의 분쟁에서 사실관계 입증을 하고
2. IBM 왓슨으로 만들 자동상담 시스템을 위한 학습데이터가 됩니다.
Intercom data back-up을 위한 용어의 정의
- Conversation : 대화방, 각각의 conversation ID가 있음.
- Conversation parts : 카톡으로 따지면 하나의 버블, Conversation > Transcript > 여기서 오간 하나하나의 대화를 Parts라고 표현함.
- 하나의 Conversation ID에 있는 Parts를 API(Retrieve a conversation)를 통해, export하는 경우, 한번에 500 parts만 리턴하는 limit 존재.
개발 API문서
developers.intercom.com: API의 전문을 파악하고 데이터 단위들의 개념파악을 할 수 있음.
github: 자바 연동의 코드적인 도움을 받을 수 있음.
Gradle
repositories {
jcenter()
}
dependencies {
compile 'io.intercom:intercom-java:2.8.1'
} Initialization
@PostConstruct
public void init(){
Intercom.setToken(managerToken);
}Conversations
//전체 대화방 목록을 가져옴.
ConversationCollection conversations = Conversation.list();
while (conversations.hasNext()) {
Conversation conversation = conversations.next();
}
// 하나의 대화방 기준으로 대화목록을 가져옴.
final Conversation conversation = Conversation.find("66");
ConversationMessage conversationMessage = conversation.getConversationMessage();
ConversationPartCollection parts = conversation.getConversationPartCollection();
List<ConversationPart> partList = parts.getPage();
for (ConversationPart part : partList) {
String partType = part.getPartType();
Author author = part.getAuthor();
String body = part.getBody();
}데이터 백업 시 속도 이슈
// 모든 대화내용을 가져온다.
ConversationCollection conversations = Conversation.list();
while (conversations.hasNext()) {
// 대화방 가져오기
Conversation conversation = conversations.next();
log.info("conversation");
// 대화들 가져오기
ConversationPartCollection parts = conversation.getConversationPartCollection();
List<ConversationPart> partList = parts.getPage();
// 대화목록
for (ConversationPart part : partList) {
System.out.println(part.getId());
}
}전체 대화를 가져온 후,
대화방의 대화ID를 추출하는 간단한 코드입니다.
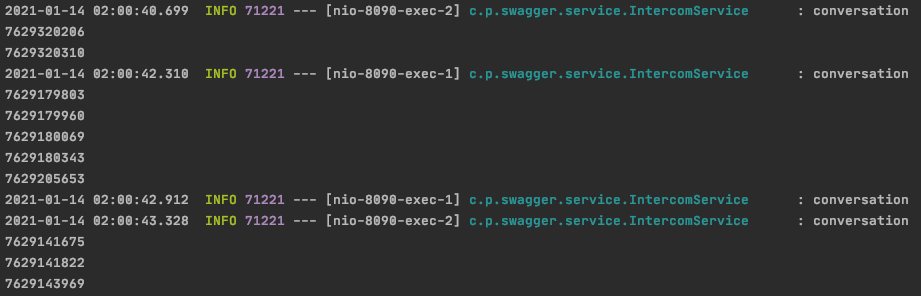
대화방을 가져오는 과정에서 1초 정도의 딜레이가 있었습니다.
원인을 파악하기 위해 로직을 디코딩하여 분석을 해 보았습니다.
conversations.hasNext() 분석
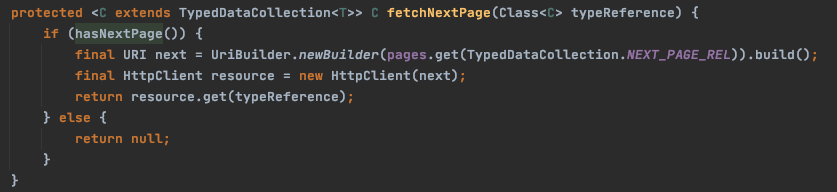
전체 대화를 가져오는 것이 아니었습니다. 페이징 처리가 되어 있고 새로운 페이지를 HttpClient로 로딩을 하고 있었습니다.
그리고 대화방에는 대화목록이 없었습니다.
conversation.getConversationPartCollection() 분석
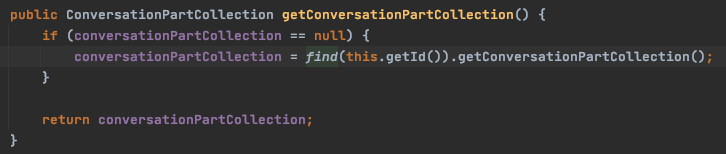
대화목록도 다시 통신을 통해 가져오고 있었습니다.
그래서
대화방 20개 가져오는데 1초,
하나의 대화방 당 대화목록을 가져오는데 1초씩 걸리면서 네트워크I/O에 따른 속도 이슈를 확인하였습니다.
해결방법
위의 페이지는 Intercom에서 제공하는 대화방 목록을 다운받을 수 있는 곳이었습니다.
저는 전체 대화방ID를 년도별 파일형태로 만든 뒤에 parallelStream을 사용하여 병렬처리를 시도하였습니다.
파일에서 대화방 리스트 추출
// 파일에서 conversationID 목록 가져오기
public void readFile(){
try{
//파일 객체 생성
File file = new File("2019_cnvList.txt");
//입력 스트림 생성
BufferedReader inFile = new BufferedReader(new FileReader(file));
String sLine = null;
List<String> list = new ArrayList<>();
while( (sLine = inFile.readLine()) != null ){
list.add(sLine);
}
inFile.close();
// 파일 라인이 많아 분산
makeCSV(list.subList(0,4999),"2019_1-5000.csv");
makeCSV(list.subList(5000,9999),"2019_5001-10000.csv");
makeCSV(list.subList(10000,14999),"2019_10001-15000.csv");
makeCSV(list.subList(15000,19999),"2019_15001-20000.csv");
makeCSV(list.subList(20000,list.size()),"2019_20001.csv");
}catch (FileNotFoundException e) {
e.printStackTrace();
}catch(IOException e){
System.out.println(e);
}
}
병렬처리
// 병렬처리
public void makeCSV(List<String> target, String fileName){
List list = new ArrayList();
Long start = System.currentTimeMillis();
target.parallelStream().forEach(id->{
System.out.println(id+ "_" + list.size());
try {
final Conversation conversation = Conversation.find(id);
if(conversation != null){
ConversationPartCollection parts = conversation.getConversationPartCollection();
List<ConversationPart> partList = parts.getPage();
for (ConversationPart part : partList) {
ExportVO exportVO = new ExportVO(conversation.getId(), part.getBody());
list.add(exportVO);
}
}
}catch (Exception e){
e.printStackTrace();
}
});
// 걸린 시간체크
Long end = System.currentTimeMillis();
long takeTime =end-start;
System.out.println("the time:"+takeTime);
System.out.println("csv Row List size:" + list.size());
File csvFile = new File(fileName);
csvUtil.makeCsvFile(ExportVO.class,csvFile,list);
}
CSV파일 만들기
// makeCsvFile
public void makeCsvFile(Class<?> clazz, File csvFile, List<?> dataList) {
try {
CsvMapper csvMapper = new CsvMapper();
CsvSchema csvSchema =
csvMapper.enable(CsvGenerator.Feature.ALWAYS_QUOTE_STRINGS)
.schemaFor(clazz) // CSV 파일로 생성할 자바 객체의 클래스 정보
.withHeader() // CSV 헤더 사용 여부
.withColumnSeparator(',') // 컬럼 간 구분자
.withLineSeparator("\n"); // 개행
ObjectWriter writer = csvMapper.writer(csvSchema);
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(new FileOutputStream(csvFile), "UTF-8");
writer.writeValues(outputStreamWriter).writeAll(dataList);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
마무리
Intercom에서 제공하는 SDK를 보면서 외부연동 API를 만들 때에 트래픽 분산을 처리를 어떻게 할 수 있는지에서 배울 수 있었습니다.
입장을 바꾸어 한꺼번에 많은 데이터를 요청하게 되면 시스템에 무리를 주게 됩니다. 시스템 트래픽을 방어하기 위해 페이징을 어떻게 구현해야할지를 잘 보여주는 API였습니다.
제가 작성한 코드는 여기에 있습니다.
'Programming > Spring' 카테고리의 다른 글
| [Spring] Spring에서 환경변수를 배열로 가져오기 (0) | 2021.01.28 |
|---|---|
| [Spring] @JsonIgnore과 @Transient 차이 때문에 발생한 could not extract ResultSet 문제 (0) | 2021.01.25 |
| [Spring] JCenter란 (0) | 2021.01.15 |
| [Spring] @Component에 잘못 알고 있었던 점 (0) | 2021.01.13 |
| [Spring] Spring에서 APPLE로그인 구현하기 (0) | 2021.01.12 |



