
- 분류 전체보기 (858)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 정보처리기사 실기 기출문제
- 공부
- kotlin querydsl
- kotlin
- CKA 기출문제
- 티스토리챌린지
- Java
- aws
- AWS EKS
- Spring
- CloudWatch
- minikube
- Kubernetes
- 오블완
- go
- 코틀린 코루틴의 정석
- Pinpoint
- kotlin coroutine
- APM
- tucker의 go 언어 프로그래밍
- 정보처리기사실기 기출문제
- Elasticsearch
- AI
- Linux
- docker
- PETERICA
- mysql 튜닝
- CKA
- golang
- 기록으로 실력을 쌓자
- Today
- Total
피터의 개발이야기
[Elasticsearch] Elasticsearch DISK IO 병목현상 및 재기동 본문
[Elasticsearch] Elasticsearch DISK IO 병목현상 및 재기동
기록하는 백앤드개발자 2022. 5. 17. 13:12
ㅁ 개요
ㅇ Elasticsearch의 data 노드가 사용하는 볼륨에 DISK IO에서 비정상적인 지표가 확인되었다.
ㅇ 원인분석을 하였지만, 트래픽도 평균을 유지하였고, Kibana에서 롱쿼리를 날리지도 않은 상태였다.
ㅇ pod가 자체적으로 restart를 하는 것이 확인되어 ES data 두 노드를 재기동하였고 증상은 해결되었다.
ㅁ Elasticsearch data의 모니터링 이유
ㅇ 144개의 컨테이너 중에서 elasticsearch data의 CPU와 메모리 사용량이 제일 높다.
ㅇ 모든 컨테이너들의 로그를 처리하고 있어서 트래픽이 높아지면 elasticsearch의 부하도 함께 증가하기 때문에 모니터링이 필요하다.
ㅇ 특히 data의 데이터 저장을 위해 disk IO가 많이 상승할 때가 있어서 평상 시에 중점적으로 모니터링을 하고 있었다.
ㅁ 용어 개념 정리
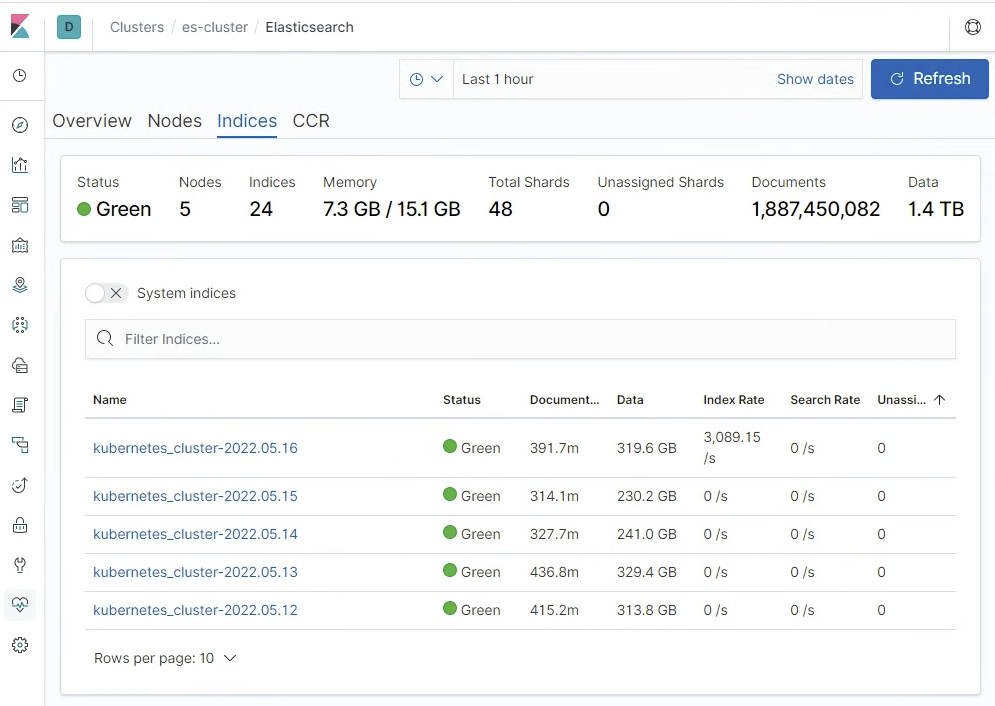
ㅇ 도큐먼트는 가장 기본 단위로 로그 한줄을 말한다.
ㅇ index는 도큐먼트의 논리적인 한 묶음이다.
ㅇ indices는 언어적으로는 index의 복수형을 뜻하고, index의 물리적인 의미로 저장소 단위 개념이다.
o shard는 indices의 분산저장 단위이다.
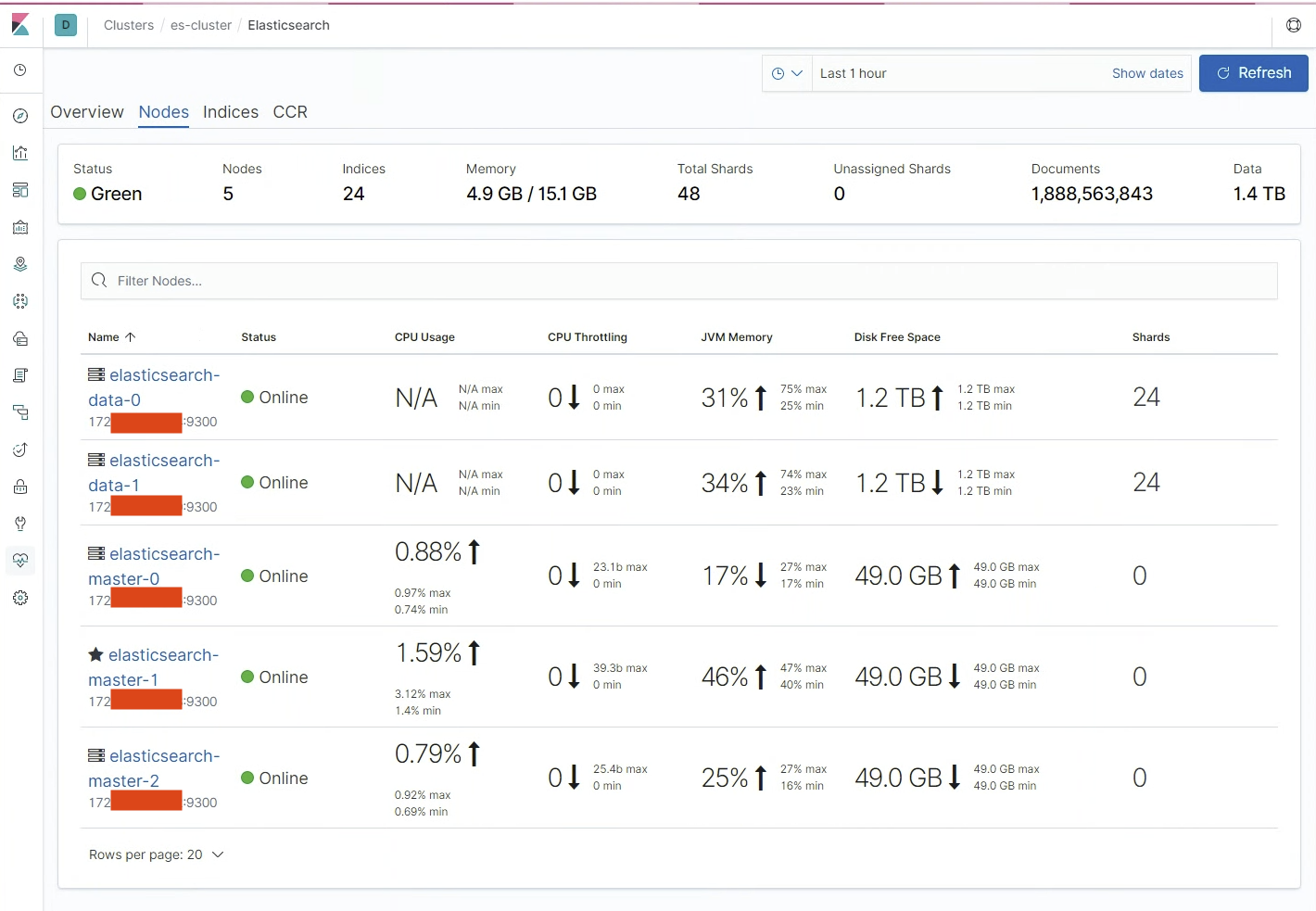
ㅇ shard는 5개의 노드 중에서 data 노드에 24씩 이중으로 저장이 된다.
ㅇ 트레픽 발생에 따라 로그량이 증가하면서 indices가 여러 샤드로 분리되고 샤드를 복제하는 과정에서
유휴시간이 급격히 줄어드는 경우가 있었다.
ㅇ 간혹 트레픽이 폭발적으로 증가한 상태에서 샤드의 복제까지 일어나는 경우
disk IO의 부족으로 병목현상이 발생할 수 있기 때문에 트래픽이 증가하는 경우 집중적으로 모니터링이 필요하다.
ㅁ CloudWatch Elasticsearch data Node의 볼륨 유휴시간 지표
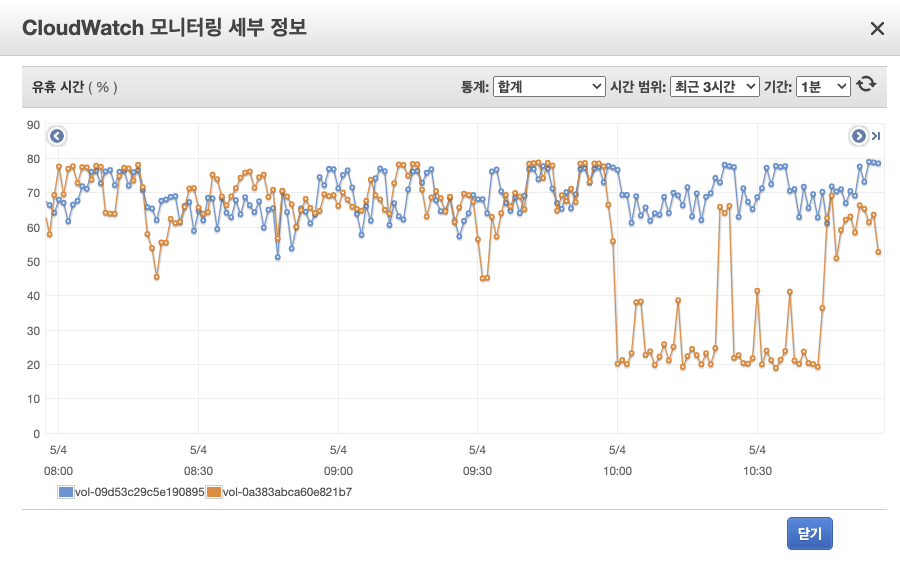
ㅇ 모니터링 중 유휴시간이 20%까지 떨어지는 특이점을 발견하여 분석을 시작하였다.
ㅇ 트래픽이 증가에 따른 부하는 아니었다. 트래픽은 오히려 평균 이하로 평이하게 인입되고 있었다.
ㅇ 샤드 복제일 가능성이 있어서 지표를 두고 보기로 하였다. 하지만 이미 새벽부터 지속적으로 발생하고 있었다.
ㅁ Elasticsearch 내부 로그 확인

ㅇ kubectl logs elasticsearch-data-1 명령을 통해 내부 로그를 확인하였다.
ㅇ 특정 에러패턴이 확인 되었고 재기동이 필요한 상황이었다.
ㅁ Elasticsearch 재기동 과정

ㅇ 문제가 되었던 data pod들을 순차적으로 재가동을 하였다.
ㅇ kubectl logs elasticsearch-data-0
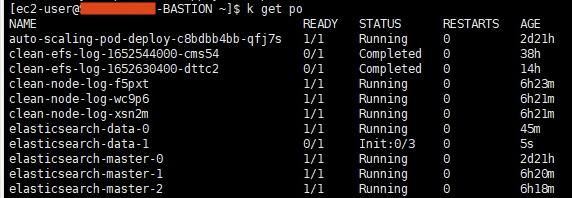
ㅇ kubectl get po 를 통해 컨테이너의 재기동을 확인 할 수 있다.
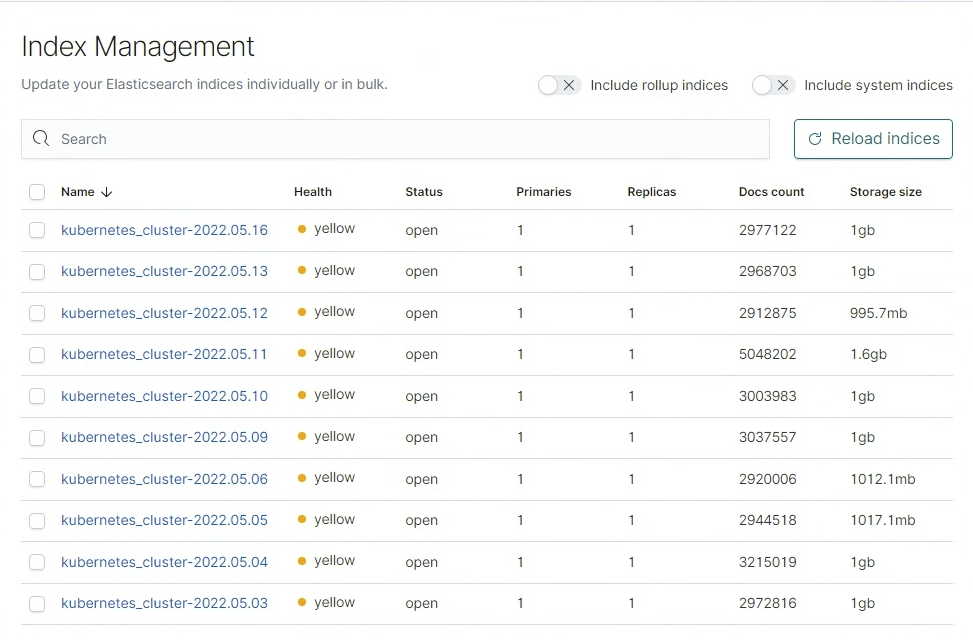
ㅇ 재가동 중에는 모든 index가 yellow 상태로 바뀐다.
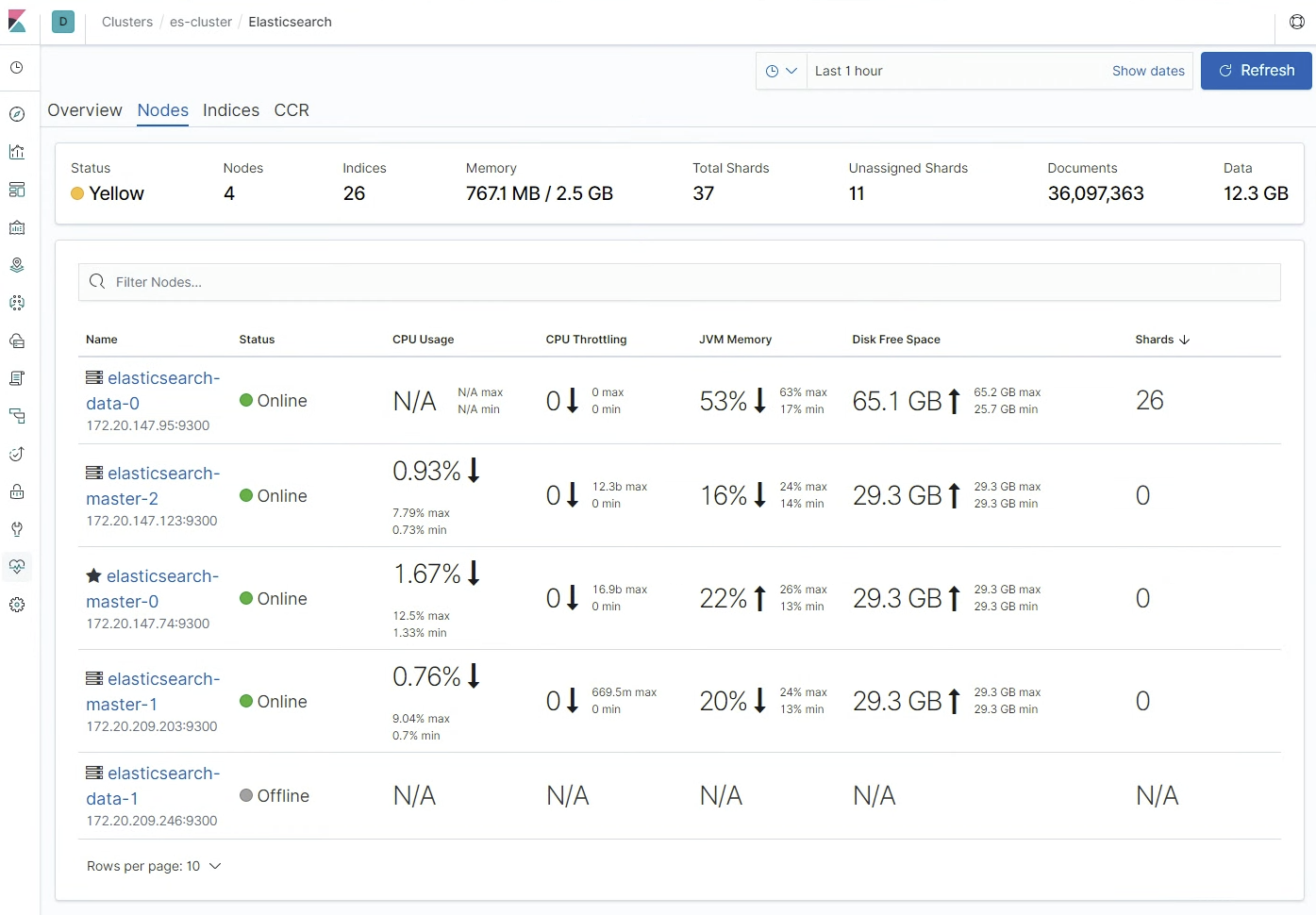
ㅇ 키바나에서 elasticsearch data-1이 Offline이 되었고, Status는 Yellow 상태가 되었다.
ㅁ Elasticsearch 재기동 후 안정화 확인
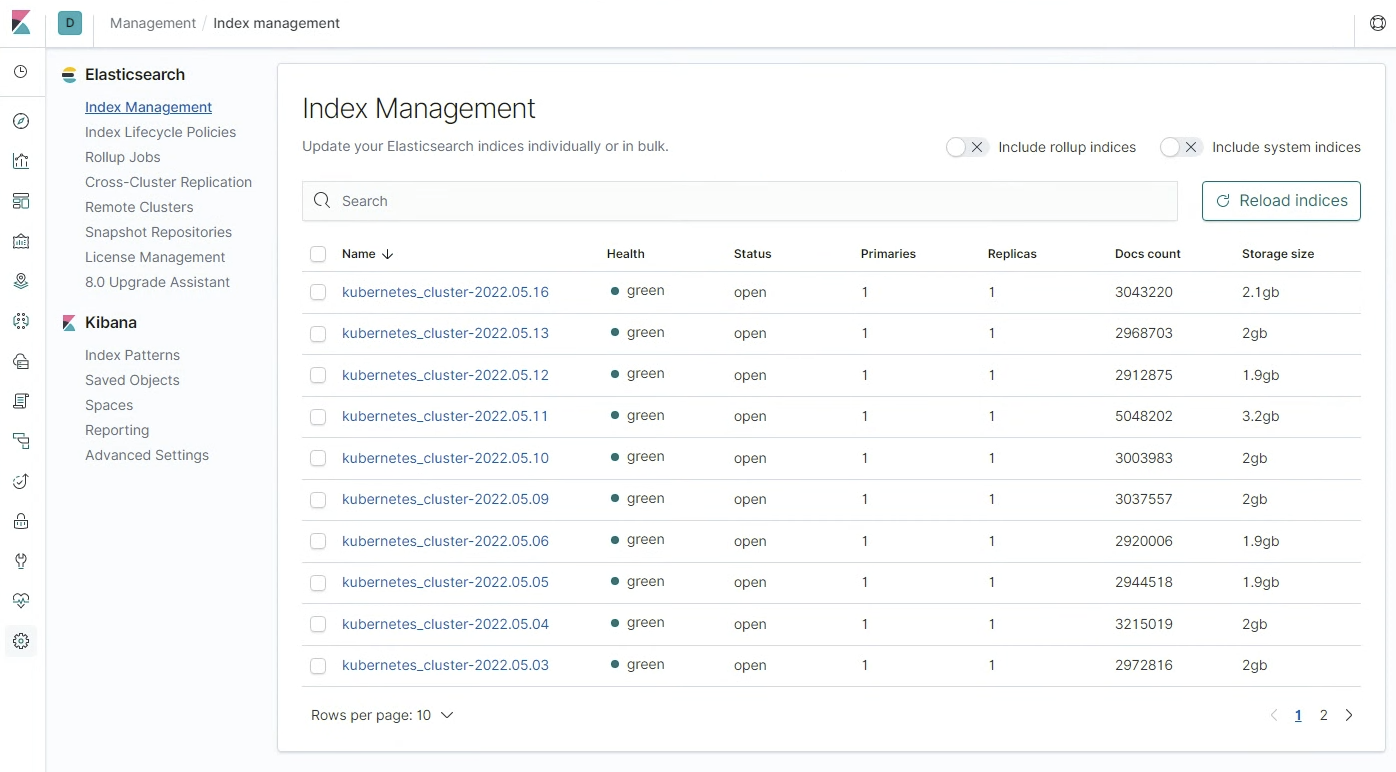
ㅇ 재기동이 완료되었고, 모든 index의 상태가 green으로 바뀌게 되었다.
ㅇ 로그 수집도, 로그 조회도 정상화 되었다.
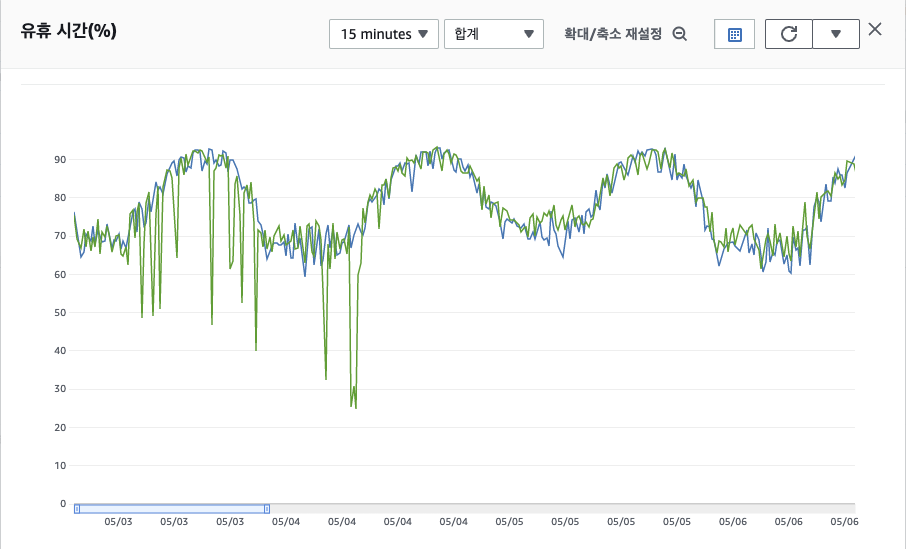
Cloud Watch의 볼륨 요휴시간 지표에서도 재기동 이후 특이점은 발견되지 않았다.
'DevOps > Elasticsearch' 카테고리의 다른 글
| [Elasticsearch] Elasticsearch rejected exception 분석 (0) | 2022.11.16 |
|---|---|
| [Elasticsearch] EFK 설치(minikube)-2 (2) | 2022.08.15 |
| [Elasticsearch] EFK 설치(minikube)-1 (0) | 2022.08.07 |
| [Elasticsearch] EFK(Elasticsearch, Fluentd, kibana)란 (0) | 2022.08.02 |
| [Elasticsearch] index vs indices (0) | 2022.05.17 |



