
- 분류 전체보기 (870)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- APM
- 오블완
- 공부
- CKA
- CloudWatch
- Spring
- docker
- 정보처리기사실기 기출문제
- AI
- Linux
- kotlin querydsl
- CKA 기출문제
- go
- AWS EKS
- 티스토리챌린지
- SRE
- kotlin coroutine
- 코틀린 코루틴의 정석
- tucker의 go 언어 프로그래밍
- Elasticsearch
- aws
- minikube
- Java
- 기록으로 실력을 쌓자
- golang
- PETERICA
- Pinpoint
- kotlin
- Kubernetes
- 정보처리기사 실기 기출문제
- Today
- Total
피터의 개발이야기
[Elasticsearch] 클러스터의 높은 메모리 사용률에 대한 원인 분석 방법 정리 본문

ㅁ 개요
ㅇ Elasticsearch Data 노드의 높은 메모리 사용량을 분석하고,
ㅇ "해결 방법을 함께 보면 좋은 사이트"를 참조하여 Elasticsearch 클러스터의 높은 메모리 사용률 문제를 분석방법을 정리하였다.
ㅁ 함께 보면 좋은 사이트
ㅇ Elasticsearch 블로그 - Elasticsearch 메모리 관리 및 문제 해결
ㅇ AWS DOC - Amazon OpenSearch Service 클러스터의 높은 CPU 사용률 문제를 해결하려면 어떻게 해야 합니까?
ㅇ 토스 - 대규모 로그 처리도 OK! Elasticsearch 클러스터 개선기
ㅁ 와탭을 통한 지표 수집
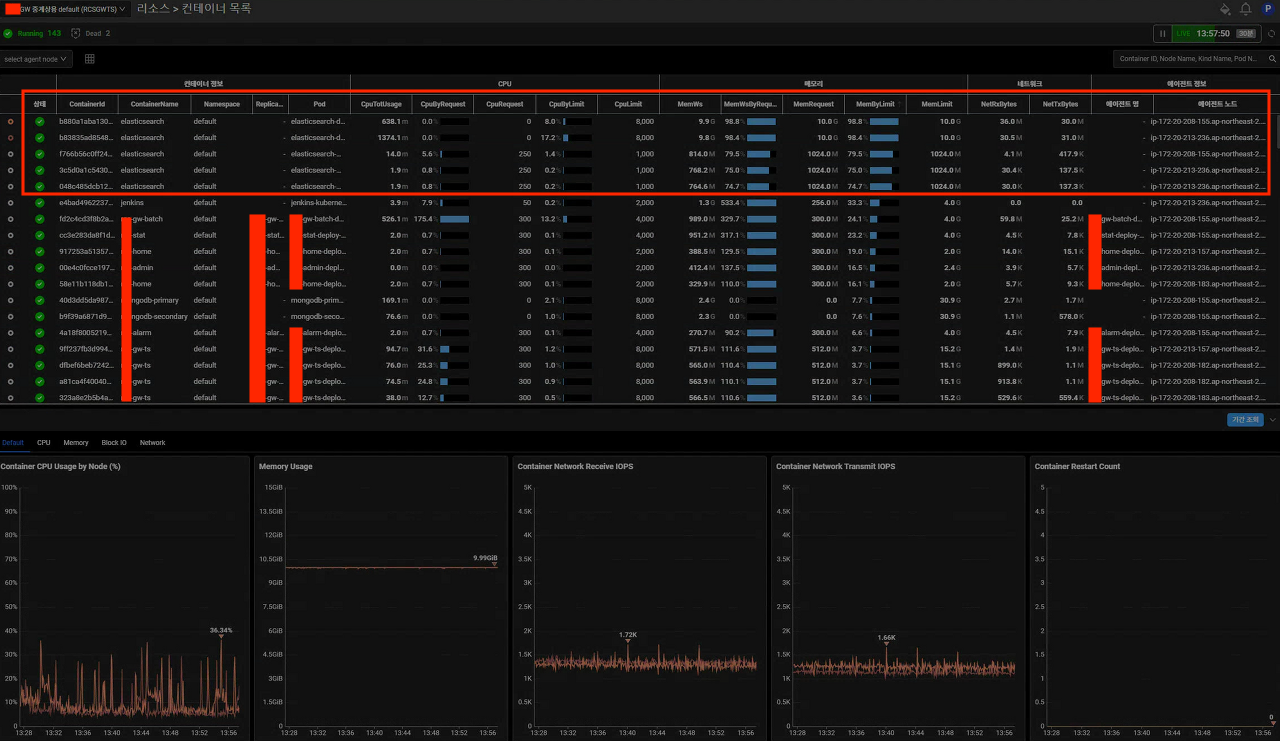
ㅇ whatap에서 수집된 컨테이너 리소스 정보이다.
ㅇ Elasticsearch의 Data 노드에 할당된 메모리 10GB 중 9.9GB를 사용 중이다.
ㅁ ElasticSearch 지표 분석
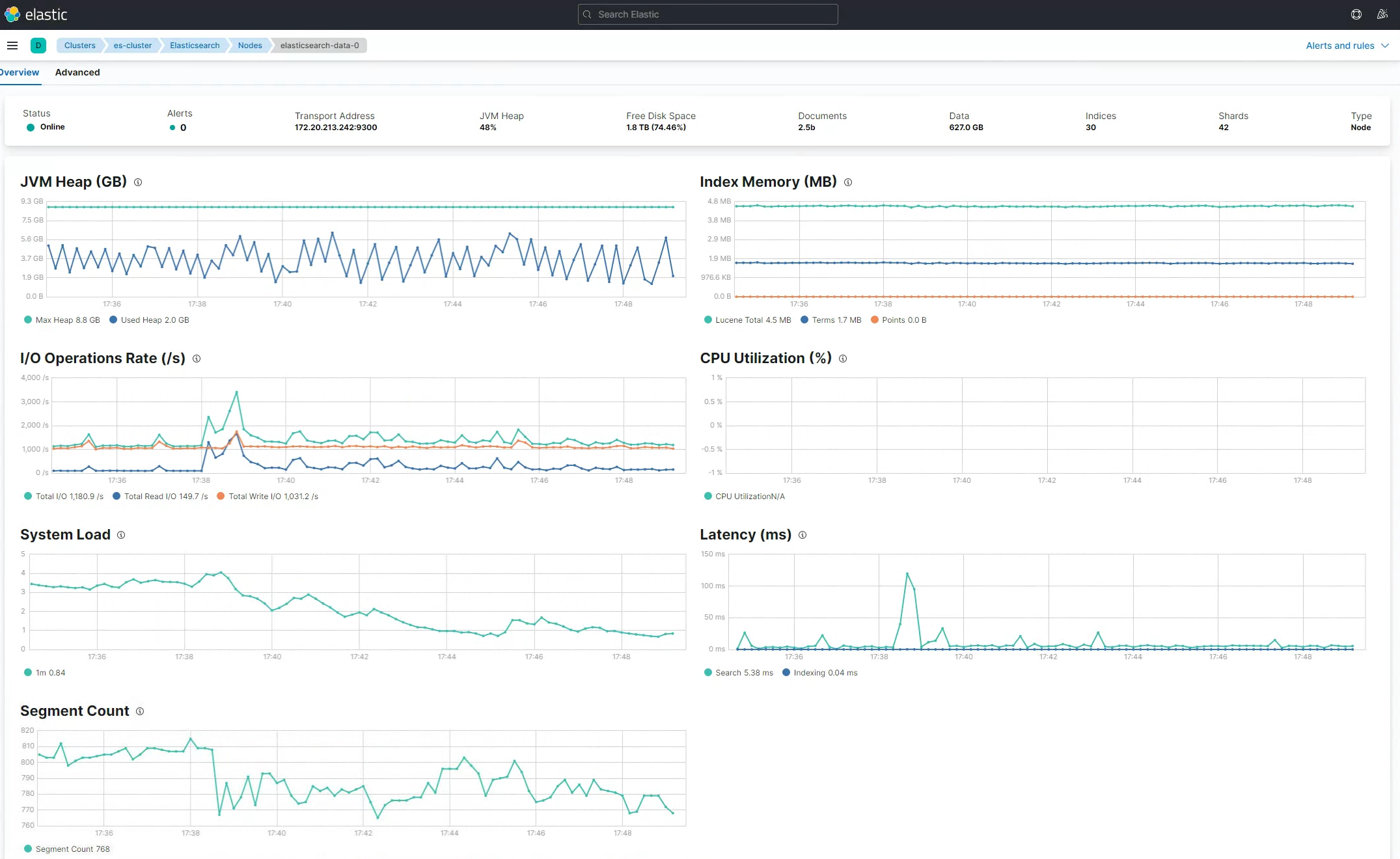
ㅇ Elasticsearch Data Node의 지표이다.
ㅇ 순간 I/O가 Read, Write IO가 올라가면서 지연이 발생할 때가 있다.
ㅁ Elasticsearch 클러스터의 높은 메모리 사용률 문제를 분석 방법
1. JVM 힙 사용량 모니터링
Elasticsearch는 JVM 위에서 동작하므로 JVM 힙 메모리 사용량을 확인하는 것이 중요하다. JVM 옵션을 통해 힙 크기를 적절히 설정하고, 힙 사용량이 너무 높지 않은지 모니터링해야 한다.
Java 애플리케이션의 경우, Elasticsearch를 사용하려면 시스템의 실제 메모리에서 일부 논리 메모리(힙)를 할당해야 합니다.
이 용량은 물리적 RAM의 절반까지가 최대여야 하며, 32GB로 제한되어야 합니다.
- elasticsearh blog 참조
JVM 메모리 사용량 확인 클러스터 노드에 있는 Java 힙의 JVM 메모리 사용량 비율을 검토하세요. JVM 메모리 사용량이 75%에 도달하면 Amazon OpenSearch Service가 CMS(동시 마크 스윕) 가비지 콜렉터를 트리거합니다. JVM 메모리 사용량이 100%에 도달하면 OpenSearch Service JVM이 종료되고 결국에는 OutOfMemory(OOM)에서 다시 시작되도록 구성됩니다.
- AWS Doc 참조
2. 필드데이터(fielddata) 메모리 사용량 확인
과도한 필드데이터 메모리 사용은 클러스터 성능 저하의 주요 원인이 될 수 있다. 필드데이터 캐시 사용량을 모니터링하고 필요한 경우 제한을 설정해야 한다.
Elasticsearch 및 Lucene에 Doc value 스토리지가 도입되기 전에는 필드에 대해 aggregation과 정렬을 하기 위해서 필드의 값들을 fielddata라는 메모리 영역으로 올려서 fielddata에서 aggregation을 수행하고 정렬을 하였었는데요, 매우 큰 인덱스의 필드들을 메모리로 올려서 사용하다 보니 Elasticsearch의 JVM 메모리가 항상 부족해지고 매우 긴 가비지 컬렉션이 발생하여 이로 인해 클러스터가 일시적으로 멈추는 현상이 빈번했습니다. 그래서 Elasticsearch는 파일 시스템을 사용하고 컬럼 기반인 Doc value storage를 도입하여 aggregation과 정렬을 수행할 때 힙 메모리를 덜 사용하고 운영체제 레벨 캐시를 적극적으로 사용하는 방향으로 발전되어왔습니다.
- 토스 글: 잘못 사용한 fielddata 옵션 참조
3. 가비지 컬렉션(GC) 로그 분석
긴 가비지 컬렉션 시간은 클러스터 성능에 큰 영향을 미친다. GC 로그를 분석하여 빈번하고 긴 GC pause가 발생하는지 확인해야 한다.
4. 노드 핫 스레드 API 사용
노드 핫 스레드 API를 사용하여 CPU를 많이 사용하는 스레드를 식별할 수 있다. 이를 통해 어떤 작업이 리소스를 많이 소모하는지 파악할 수 있다.
ㅇ 노드 핫 스레드 API의 출력 예(AWS DOC 참조)
GET _nodes/hot_threads
100.0% (131ms out of 500ms) cpu usage by thread 'opensearch[xxx][search][T#62]'
10/10 snapshots sharing following 10
elements sun.misc.Unsafe.park(Native Method)
java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
java.util.concurrent.LinkedTransferQueue.awaitMatch(LinkedTransferQueue.java:737)
java.util.concurrent.LinkedTransferQueue.xfer(LinkedTransferQueue.java:647)
java.util.concurrent.LinkedTransferQueue.take(LinkedTransferQueue.java:1269)
org.opensearch.common.util.concurrent.SizeBlockingQueue.take(SizeBlockingQueue.java:162)
java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)
java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
java.lang.Thread.run(Thread.java:745)
5. 작업 관리 API 활용
작업 관리 API를 사용하여 현재 실행 중인 검색 쿼리들을 확인할 수 있다. 이를 통해 리소스를 많이 사용하는 장기 실행 쿼리를 식별할 수 있다.
높은 CPU를 소비하는 검색 스레드 풀은 검색 쿼리가 OpenSearch Service 클러스터를 압도하고 있음을 나타냅니다. 하나의 장기 실행 쿼리로 인해 클러스터가 압도될 수 있습니다. 클러스터에서 수행되는 쿼리의 증가는 검색 스레드 풀에도 영향을 미칠 수 있습니다.
단일 쿼리로 CPU 사용량이 증가하는지 확인하려면 작업 관리 API를 사용하세요. 예를 들면 다음과 같습니다.
GET _tasks?actions=*search&detailed작업 관리 API는 클러스터에서 실행 중인 모든 활성 검색 쿼리를 가져옵니다. 자세한 내용은 Elasticsearch 웹 사이트의 작업 관리 API를 참조하세요. AWS Doc 참조
6. 클러스터 상태 및 통계 확인
Elasticsearch API를 사용하여 클러스터의 전반적인 상태와 통계를 확인한다. 이를 통해 메모리 사용량, 인덱스 크기, 샤드 분배 등을 파악할 수 있다. 위의 그림인 ElasticSearch 지표 분석와 같이 가시적인 모니터링 지표를 통해 문제에 접근 할 수 있다.
7. 매핑 및 인덱스 설정 검토
불필요한 필드 인덱싱이나 과도한 동적 매핑으로 인한 메모리 사용량 증가를 방지하기 위해 매핑 설정을 검토한다. 필요한 경우 dynamic field 옵션을 false로 설정하거나 flattened type을 사용할 수 있다.
또 하나의 Elasticsearch 클러스터의 안정성을 위협하는 것은 mapping explosion입니다.
유입되는 로그가 많아지고 규모가 커질수록 인덱스 매핑이 정말 중요해지는데요, Elasticsearch 클러스터가 느려지고 불안정한 경우 원인 분석을 하면 대부분 인덱스 매핑이 비효율적으로 정의되어 있는 경우가 많습니다. (토스 글 - 인덱스 매핑 참조)
ㅁ 마무리
서비스가 성장할 수록 수많은 로그를 처리하는 방법은 대량트래픽을 처리하는 서비스 개발 못지 않게 중요한 과제였다. 고민 속에 있던 문제점을 AWS, Elasticsearch 블로그, 토스 글을 통해 정리할 수 있었다. 위에 정리한 분석 방법들을 통해 Elasticsearch 클러스터의 메모리 사용률 문제의 원인을 파악하고, 적절한 최적화 방안을 수립할 수 있을 것이다.
'DevOps > Elasticsearch' 카테고리의 다른 글
| [Elasticsearch] received plaintext http traffic on an https channel, closing connection Netty4HttpChannel 해결 방법 (0) | 2024.08.04 |
|---|---|
| [Elasticsearch] Docker로 Elasticsearch 설치 및 테스트하기 (0) | 2024.08.03 |
| [Elasticsearch] Data Node 볼륨 병목현상 확인 및 처리 (0) | 2023.01.16 |
| [Elasticsearch] Elasticsearch rejected exception 분석 (0) | 2022.11.16 |
| [Elasticsearch] EFK 설치(minikube)-2 (2) | 2022.08.15 |



