
- 분류 전체보기 (858)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- kotlin coroutine
- kotlin querydsl
- 오블완
- go
- Kubernetes
- golang
- docker
- AI
- Spring
- 티스토리챌린지
- 공부
- Java
- PETERICA
- APM
- tucker의 go 언어 프로그래밍
- AWS EKS
- Pinpoint
- 기록으로 실력을 쌓자
- kotlin
- CKA 기출문제
- CKA
- aws
- 코틀린 코루틴의 정석
- 정보처리기사실기 기출문제
- Linux
- Elasticsearch
- CloudWatch
- minikube
- mysql 튜닝
- 정보처리기사 실기 기출문제
- Today
- Total
피터의 개발이야기
[kubernetes] EKS fail-over 상황정리 및 방어방법 본문

ㅁ 개요
ㅇ EKS에 순단이 발생하여 원인 파악을 위해 이벤트를 보는 방법([kubernetes] Events 보는 방법)을 정리하였다.
ㅇ AWS에 장애 상황에 대해 문의를 하였고, EKS fail-over 상황이 발생한 것을 확인 할 수 있었다.
ㅇ EKS 장애를 통해 장애 인지 및 모니터링을 위한 개선점을 도출하여, 그 과정을 정리하였다.
ㅇ 이 번 글에서는 EKS fail-over 시 발생 현상을 정리하였고, kubectl 수행 시 방어코드를 작성해 보았다.
1편 [kubernetes] EKS fail-over 상황정리 및 방어방법
2편 [Kubernetes] 쿠버네티스API 서버 CURL 접속 방법
3편 [Kubernetes] Spring에서 쿠버네티스 Pod 정보조회
4편 [kubernetes] kubernetes event exporter
ㅁ EKS 이벤트 확인
kubectl get events --sort-by='.metadata.creationTimestamp' -A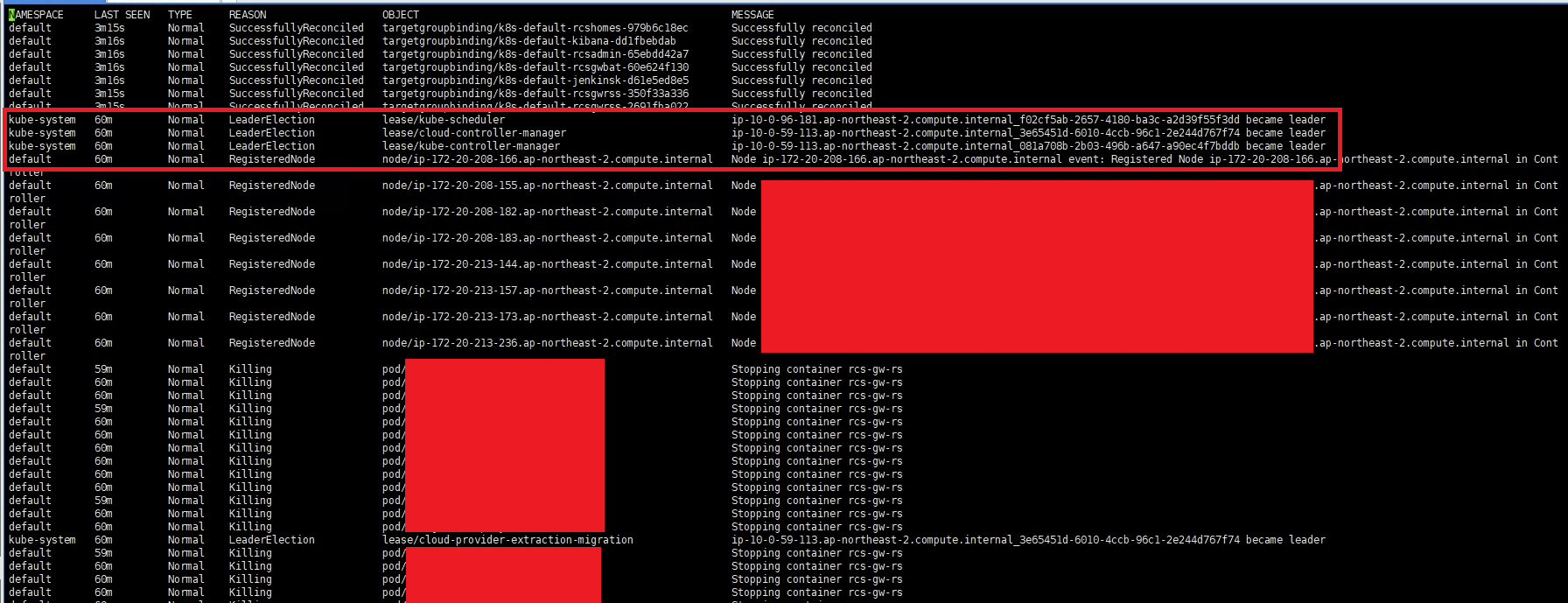
kube-system 60m Normal LeaderElection lease/kube-scheduler ip-10-0-96-181.ap-northeast-2.compute.internal_f02cf5ab-2657-4180-ba3c-a2d39f55f3dd became leader
kube-system 60m Normal LeaderElection lease/cloud-controller-manager ip-10-0-59-113.ap-northeast-2.compute.internal_3e65451d-6010-4ccb-96c1-2e244d767f74 became leader
kube-system 60m Normal LeaderElection lease/kube-controller-manager ip-10-0-59-113.ap-northeast-2.compute.internal_081a708b-2b03-496b-a647-a90ec4f7bddb became leader
kube-system 60m Normal LeaderElection lease/cloud-provider-extraction-migration ip-10-0-59-113.ap-northeast-2.compute.internal_3e65451d-6010-4ccb-96c1-2e244d767f74 became leader
kube-system 59m Normal LeaderElection lease/cp-vpc-resource-controller ip-10-0-96-181.ap-northeast-2.compute.internal_02b20544-f4b3-44da-a735-58a0535950de became leader
kube-system 59m Normal LeaderElection configmap/cp-vpc-resource-controller ip-10-0-96-181.ap-northeast-2.compute.internal_02b20544-f4b3-44da-a735-58a0535950de became leader
kube-system 59m Normal LeaderElection configmap/eks-certificates-controller ip-10-0-59-113.ap-northeast-2.compute.internal became leader
kube-system 59m Normal LeaderElection lease/eks-certificates-controller ip-10-0-59-113.ap-northeast-2.compute.internal became leaderㅇ EKS 마스터 노드가 문제가 생기면서 fail-over 과정 중에 대체 노드의 컨트롤러를 선택하는 과정을 확인 할 수 있었다.

ㅇ AWS에서도 EKS의 고가용성을 고려해 다중화가 되어 있고, fail-over로 서버가 교체될 경우 API 호출 오류가 발생할 수 있다고 안내하고 있다.
ㅇ 결국 해결책은 이 문제가 발생하는 경우 성공할 때까지 API 작업을 재시도해야한다.
ㅇ 그래도 AWS 강점은 자체 모니터링을 통해 복구작업이 자동으로 이루어져으며, 1분안에 fail-over가 처리되어 큰 장애는 막을 수 있었다.
ㅁ Fail-over시 kubectl 에러 상황
# auth에러
error: You must be logged in to the server (Unauthorized)
# connection refuse 에러 발생
The connection to the server 10.100.0.1:443 was refused - did you specify the right host or port?
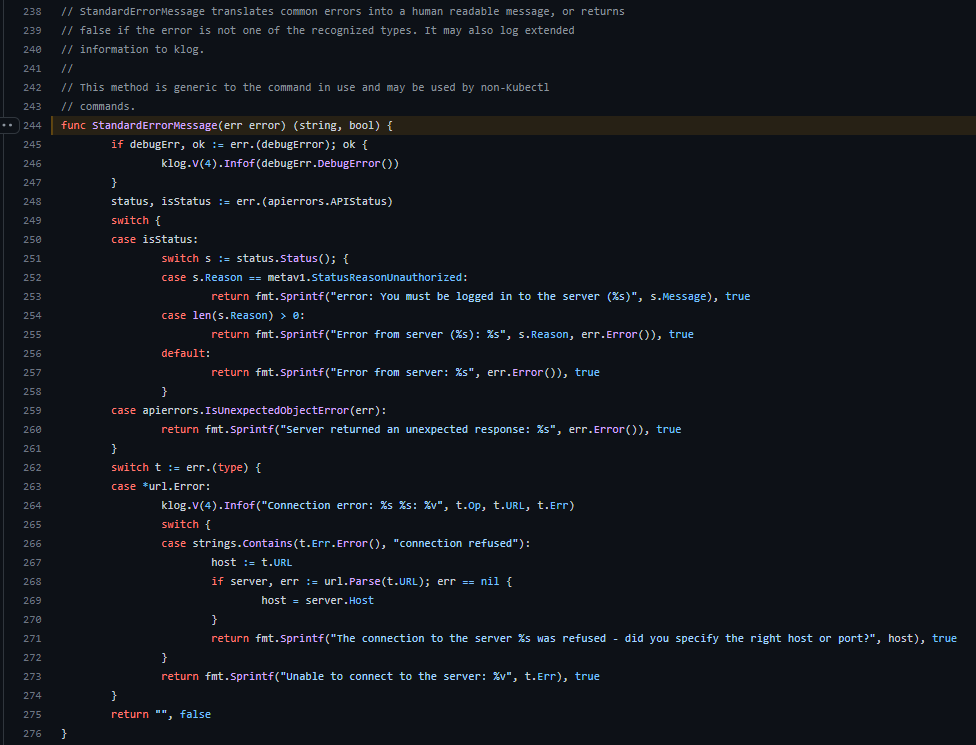
ㅇ 위 에러의 처리는 이곳에서 이루어졌다.
ㅇ 마스터 노드의 컨테이너가 제대로 작동하지 않을 때에 StandardErrorMessage에서 처리된다.
ㅁ 방어방법 1, $?
while true
do
echo "----------------------------------------------------------------------------------------"
echo $(date +"%Y-%m-%d %H:%M:%S")
kubectl get po
if [ $? -eq 0 ]
then
echo "-- success --"
else
echo "----------------------------------------------------------------------------------------"
fi
sleep 1
done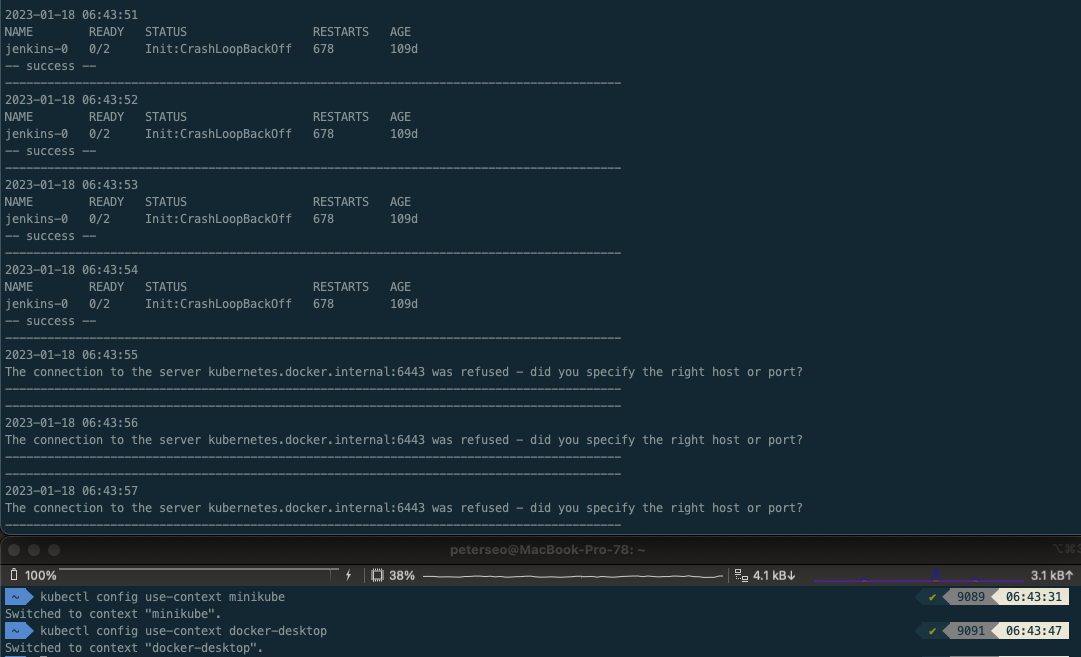
ㅇ $?의 값을 활용하는 방법이다.
ㅇ 이는 shell의 마지막 명령어의 성공여부를 판단할 수 있다.
ㅇ kubectl 실패 재현은 다중 클러스터 접근 방법을 활용하여 구동되지 않는 context로 변경하였다.
ㅁ 방어방법 2, White Check
while true
do
echo "----------------------------------------------------------------------------------------"
echo $(date +"%Y-%m-%d %H:%M:%S")
kubectl get po -o wide --no-headers > po.temp
WHITE_CNT=`grep kubectl-test-deploy po.temp | wc -l`
# 필수 항목체크, 에러가 발생하면 카운트가 0
if [ "$WHITE_CNT" -lt 1 ]
then
echo "-- fail --"
sleep 30
else
echo "-- success--"
fi
sleep 1
done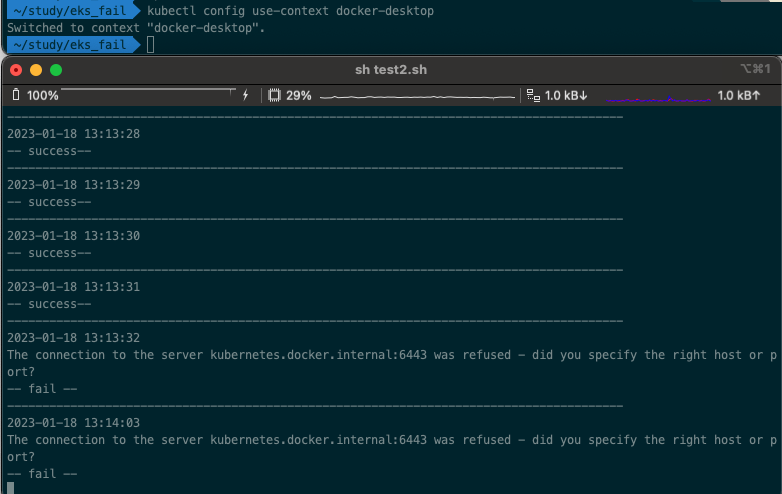
ㅇ 테스트를 위해 context를 변경하였고, fail 로그와 함께 30초 sleep이 적용되었다.
ㅁ 함께 보면 좋은 사이트
Amazon EKS 클러스터 Kubernetes 버전 업데이트 - Amazon EKS
Amazon EKS는 가용성 높은 제어 영역을 실행하지만, 업데이트 중에 심각하지 않은 서비스 중단이 발생할 수도 있습니다. 예를 들어 API 서버를 종료하고 새 Kubernetes 버전을 실행하는 새 API 서버로 교
docs.aws.amazon.com
GitHub - kubernetes/kubectl: Issue tracker and mirror of kubectl code
Issue tracker and mirror of kubectl code. Contribute to kubernetes/kubectl development by creating an account on GitHub.
github.com



